
Ces derniers jours, je me suis cassé les dents sur l’utilisation de l’appel système getdents sous Linux qui permet de lire le contenu d’un répertoire et vient en remplacement de readdir.
Sous Linux, un répertoire peut être vu comme étant un fichier recensant tous les fichiers présents dans le répertoire, le tout sous la forme d’un tableau.
Chaque case du tableau est divisée est quatre parties donnant des informations sur un fichier. Cette structure est un dirent (pour directory entry) et a la forme suivante :
1
2
3
4
5
6
7
struct dirent
{
long d_ino; /* inode number */
off_t d_off; /* offset to this dirent */
unsigned short d_reclen; /* length of this dirent */
char d_name [NAME_MAX+1]; /* file name (null-terminated) */
}
Le numéro d’inode et l’offset prennent chacun 4 octets. Le d_reclen tient sur 2 octets et correspond à la taille du dirent en octets.
La taille du dirent est en effet variable, car le nom du fichier (d_name) est variable. La taille du dirent semble être toujours arrondie pour être un multiple de 2 (ou 4 ?).
Le nom du fichier se termine par un octet nul. Les octets qui suivent pour compléter le dirent (après l’octet nul) semblent plus ou moins aléatoires.
Les principales différentes entre l’appel readdir(2) et l’appel getdents(2) sont que readdir lit un seul dirent à la fois et renvoi la longueur du nom de fichier dans d_reclen alors que getdents lit un flux et renvoi plusieurs dirent à la fois et que chaque d_reclen correspond à un dirent entier.
J’ai passé pas mal de temps à comprendre sous quelle forme getdents nous donnait ce flux de données.
Les premiers essais étaient plus ou moins concluants. Je parvenais à obtenir la liste de quelques fichiers avant que le programme ne s’arrête bizarrement ou se mette à tourner en boucle sur un nom de fichier.
J’ai ensuite testé une autre méthode : en demandant à getdents de me lire 10 octets je parvenais bien à obtenir le début du dirent et pouvait alors ajuster le nombre d’octets à lire ensuite pour tomber pile à la fin du dirent en cours. Mais de toute évidence cela ne fonctionnait pas, car au second lancement getdents me renvoyait à nouveau les mêmes 10 octets.
En fait, je pensais que getdents agissait à la façon d’un read(2) et qu’il allait tronquer le dernier dirent, obligeant les programmeurs à recoller les morceaux à la prochaine lecture. Je n’aurais sans doute pas perdu autant de temps si je m’étais attardé sur les valeurs de retour de getdents qui me signalait que quelque chose clochait.
Le truc, c’est que l’on passe un argument à getdents (dans edx) qui correspond à la taille du buffer où seront enregistrés les dirents et que getdents le rempli de manière courtoise et non pas comme un wisigoth retournant une panse de brebis.
Par conclusion quand je demandais à getdents de me lire 10 octets il râlait parce que ça ne lui laissait pas assez de place pour stocker le moindre dirent et si je lui demande de lire pour une place de 2 dirents et demi il va s’arrêter à la fin du second sans tronquer le troisième.
Pour nous aider, getdents renvoi (dans eax) la taille en octets des données qu’il a bien voulu lire.
On a donc une suite de dirents qui ressemble à ça :
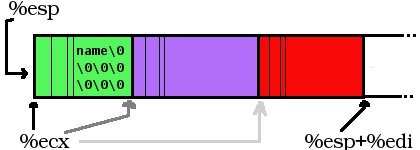
Dans mon code, j’alloue un buffer de 266 octets sur la pile (c’est peu et ça oblige à faire pas mal d’appels à getdents mais c’était seulement pour tester et c’est facilement modifiable). Le début du buffer est donc pointé par %esp.
Le registre %ecx est utilisé pour pointer au début du dirent en cours d’analyse. Le registre %edi garde en mémoire le nombre d’octets lu pour chaque appel à getdents. À chaque fois que %ecx-%esp est égal ou supérieur à %edi c’est signe qu’il faut re-remplir notre buffer en appelant à nouveau getdents.
Voilà le code (à compiler par nasm -f elf getdents.s puis gcc -o getdents getdents.o par exemple). Si vous avez des conseils pour l’optimisation n’hésitez pas à faire des remarques, je suis loin de connaître toutes les instructions asm.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
section .bss
fd resd 0
section .data
dir db "."
global main
section .text
main :
mov ebx, dir ;répertoire courant
xor ecx, ecx
xor edx, edx
mov eax, 5 ;ouverture
int 0x80
mov [fd], eax ;descripteur de fichier
sub esp, 0x10A ;alloue un buffer de 266 octets
readfile:
mov ebx, [fd]
mov ecx, esp ;ecx pointe sur le début du buffer
mov edx, 0x10a ;on utilise tout l'espace du buffer
mov eax, 141 ;getdents
int 0x80
cmp eax, 0 ;getdents retourne le nombre d'octets lus
jle endloop ;0 en cas de fin de répertoire et -1 en cas d'erreur
mov edi, eax ;nombre d'octets lus stocké dans edi
readbuf:
mov edx, [ecx+8] ;taille dirent
and edx, 0x0000FFFF ;word
mov ebx, ecx
add ebx, 10 ;ebx=filename
xor esi, esi
incr: ;calcule la longueur du nom de fichier
inc esi
cmp byte [ebx+esi], 0
jne incr
mov edx, esi ;nombre d'octets à écrire
mov esi, ecx ;sauvegarde ecx
mov ecx, ebx ;ecx=filename
mov ebx, 1 ;file handle, ou l'on écrit
mov eax, 4 ;write
int 0x80
;retour à la ligne
mov byte [esp], 0x0a ;nous n'avons plus besoin du premier dirent
mov edx, 1
mov ecx, esp
mov ebx, 1
mov eax, 4 ;write
int 0x80
mov ecx, esi ;restaure ecx=debut du dirent
mov edx, [ecx+8]
and edx, 0x0000FFFF
add ecx, edx ;ecx pointe sur le prochain dirent
mov esi, ecx
sub esi, esp
cmp esi, edi
jge readfile
jmp readbuf
endloop:
add esp, 0x10A ;libère l'espace utilisé par le buffer
mov eax, 6 ;close
mov ebx, [fd]
int 0x80
mov ebx, 0
mov eax, 1 ;exit
int 0x80
Published January 09 2011 at 19:44