
J’ai commencé à bouquiner le livre Python Machine Learning par Sebastian Raschka qui semble très prometteur, mais ayant des souvenirs lointains d’algèbre linéaire il a fallu que je me rafraîchisse un peu la mémoire (et avec plaisir) via le site Méthode Maths.
Le livre rentre dans le vif du sujet avec le perceptron, un classifieur linéaire dont le but est donc de séparer des éléments en deux ensembles en dressant une droite (si les éléments n’ont que deux caractéristiques) ou un hyperplan (si plus de deux caractéristiques).
Représenter graphiquement le fonctionnement d’un perceptron se fait généralement à l’aide d’éléments à deux caractéristiques (X1 et X2) car plus simple à représenter. On mettra par exemple X1 sur les abscisses et X2 sur les ordonnées.
L’objectif du perceptron est de trouver des poids W0, W1 et W2 de façon à ce que l’on puisse séparer les éléments avec la droite d’équation suivante :
1
W0 + W1*X1 + W2*X2 = 0
En prenant les caractéristiques X1 et X2 de chaque élément le classifieur distinguera d’un côté ceux pour lesquels le résultat de l’équation est supérieur à 0 et ceux pour lesquels le résultat est inférieur à zéro. Graphiquement on pourrait marquer en rouge les éléments à résultats positifs et en bleu ceux à résultats négatifs.
La magie du perceptron réside dans sa faculté à trouver lui-même des valeurs de W0, W1 et W2 par ajustement, le tout à l’aide de calculs simples. On peut trouver du contenu de l’auteur en rapport avec le chapitre correspondant ici et avec plus de code là.
J’ai trois reproches à faire sur ce chapitre :
Premièrement le théorème de convergence du perceptron (qui démontre pourquoi on finit par obtenir un résultat) n’est pas mentionné, mais à la décharge de l’auteur les ressources que l’on peut trouver sur le web sont généralement dans un langage trop mathématique :(
Deuxièmement la droite de décision n’est pas véritablement tracée dans le code donné utilisant matplotlib. Il utilise à la place un ListedColormap qui remplit les deux zones avec des couleurs différentes de chaque côté de la droite (grosso modo il parcourt tous les pixels de la surface en avançant de 0.02). C’est ce qui explique l’aspect hachuré de la droite dans son exemple.
Troisièmement on ne voit pas les différentes étapes qui font bouger la droite de décision et fonction du changement des poids.
Pour m’aider à mieux comprendre ce qu’il se passe j’ai choisi de générer des images de la progression d’un perceptron en 15 étapes (travail sur 15 éléments mal classifiés). J’ai pris comme base un autre code de perceptron pour l’améliorer. J’espère que ça aidera d’autres personnes qui ont aussi du mal à se représenter ce qu’il se passe.
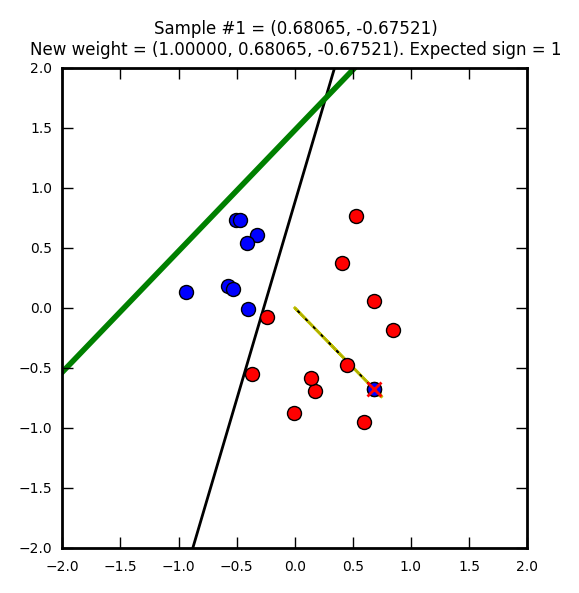
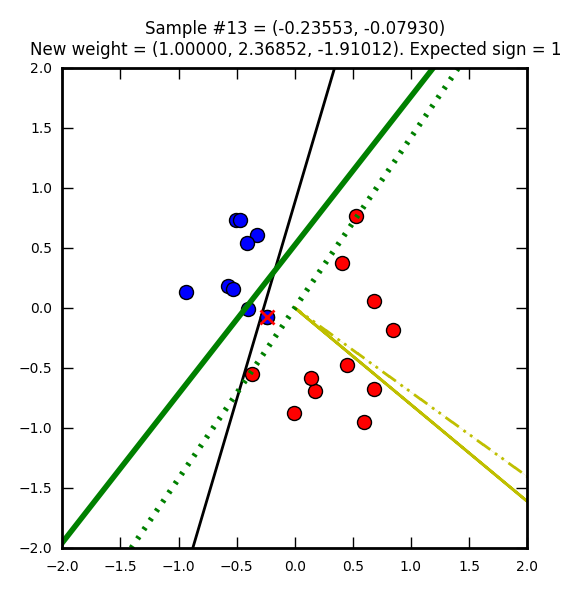
Première étape : on part avec des poids nuls (W0 = W1 = W2 = 0). Le vecteur représentant ces poids nuls n’est pas représenté sur l’image, car ce serait juste un point.
La ligne droite noire représente une solution que l’on pourrait qualifier d’optimale (on doit se rapprocher de cette solution).
Le point bleu marqué d’une croix rouge est un élément qui a été mal classifié (supposé bleu (-1) mais en réalité rouge (1)).
Le trait jaune représente le vecteur après correction (après prise en compte de la mauvaise classification). Ici le taux d’apprentissage (learning rate) est de 1 ce qui explique que le vecteur atteigne le point représentant l’élément mal classifié. Avec un taux plus petit il ne l’attendrait pas même s’il irait dans la même direction.
Sur le trait jaune, on voit une ligne noire hachurée qui est un vecteur représentant la modification par rapport au précédent poids (ici on part d’un vecteur nul donc les traits se superposent).
Enfin la ligne verte représente la droite de décision après la mise à jour du vecteur.
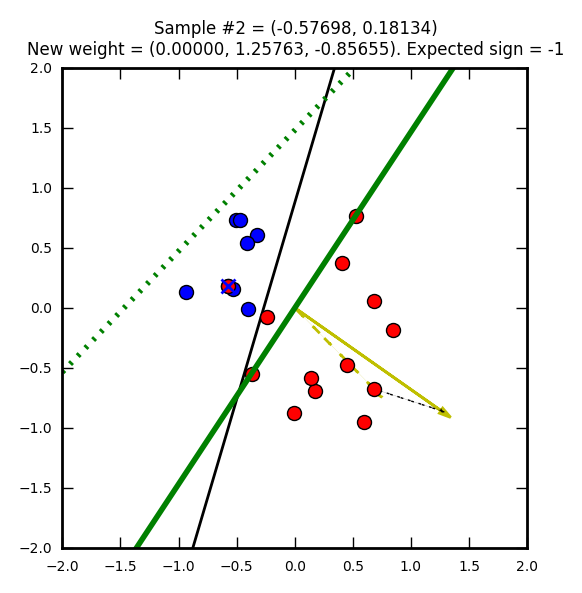
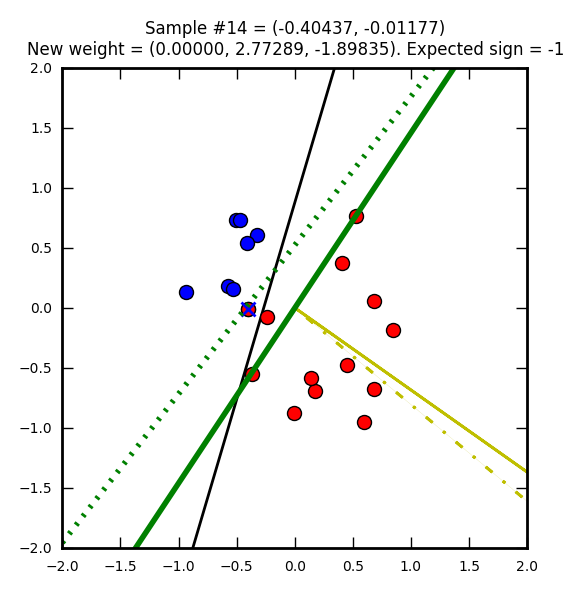
Seconde étape, cette fois avec un élément que l’on supposait rouge, mais qui est en réalité bleu. Le vecteur de poids (jaune) est mis à jour pour apprendre de cette erreur. Notez que j’ai choisi de faire partir ce vecteur de 0, 0 (pour qu’on puisse mieux le voir dans les images) mais on aurait pu le placer n’importe où ailleurs.
La ligne verte hachurée représente l’ancienne droite de décision, la ligne verte pleine est la nouvelle.
Notez comme la droite de direction est systématiquement perpendiculaire au vecteur de poids.
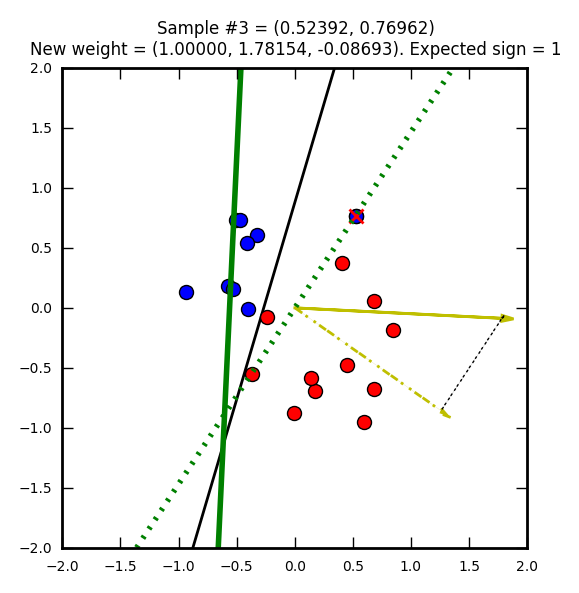
Troisième étape : un élément rouge injustement marqué bleu.
Étant donné que l’on travaille sur deux dimensions la droite de solution est une équation du type y = ax + b.
Pour reprendre l’équation initiale :
1
W0 + W1*X1 + W2*X2 = 0
Avec X1 sur les abscisses et X2 sur les ordonnées, on peut alors écrire :
1
W2*X2 = -W1*X1 - W0
et :
1
X2 = - (W1/W2)*X1 - (W0/W2)
Donc le coefficient directeur est -(W1/W2) et l’ordonnée à l’origine est -W0/W2. 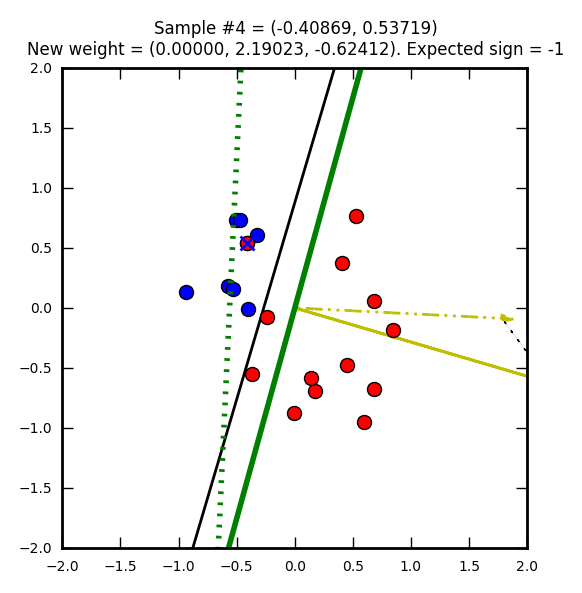
Le perceptron suit son chemin de correction…
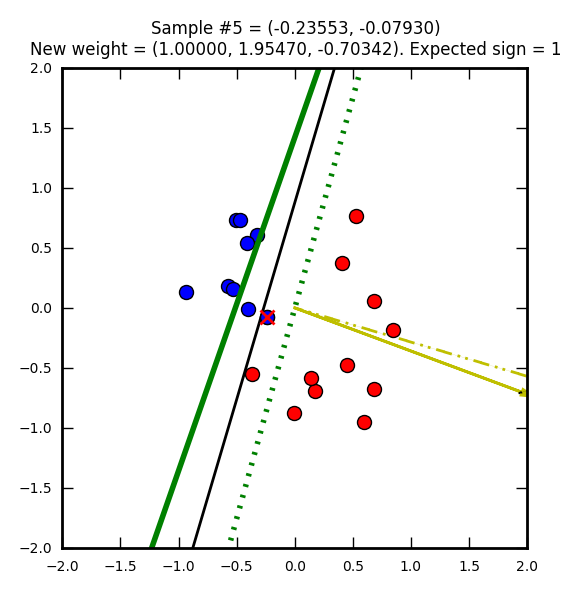
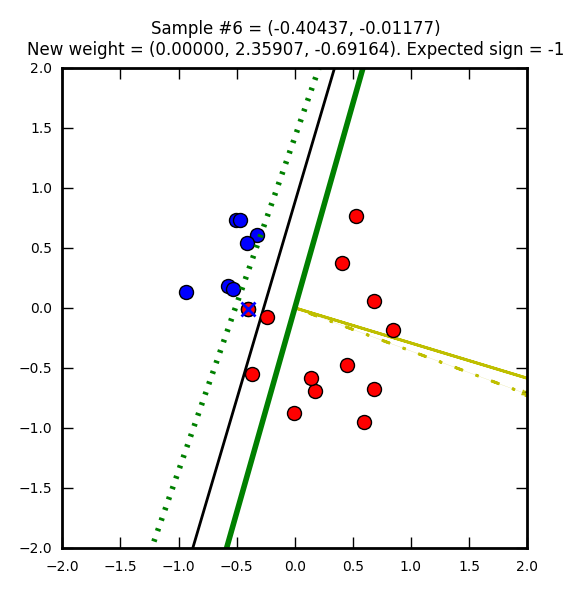
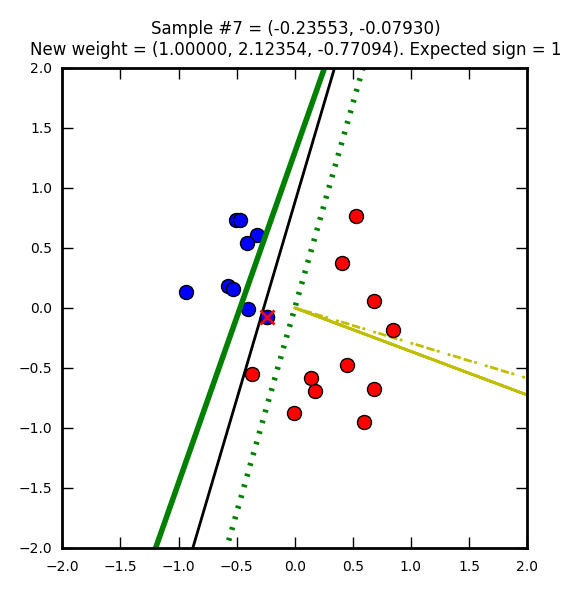
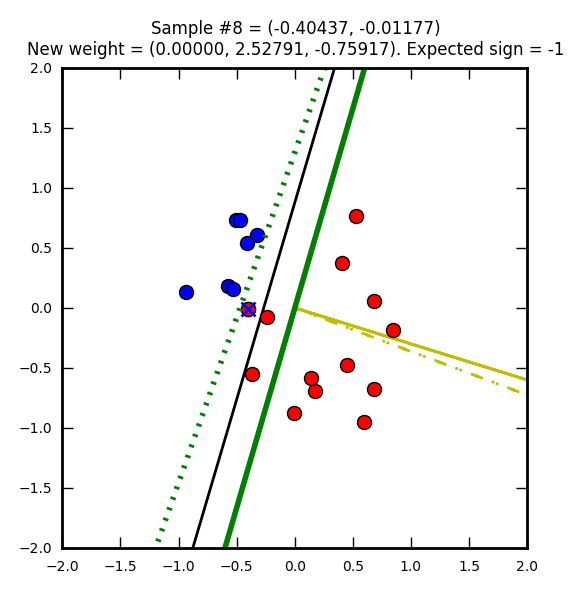
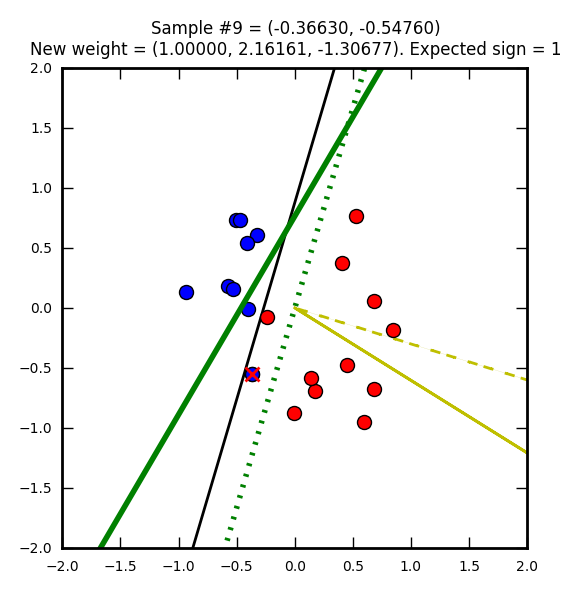
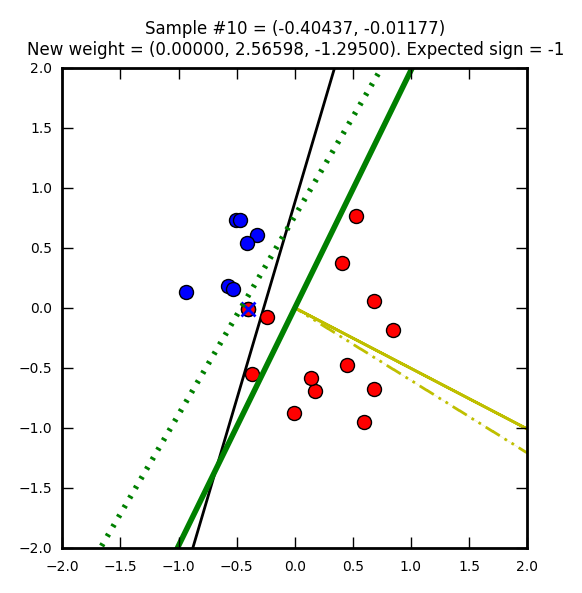
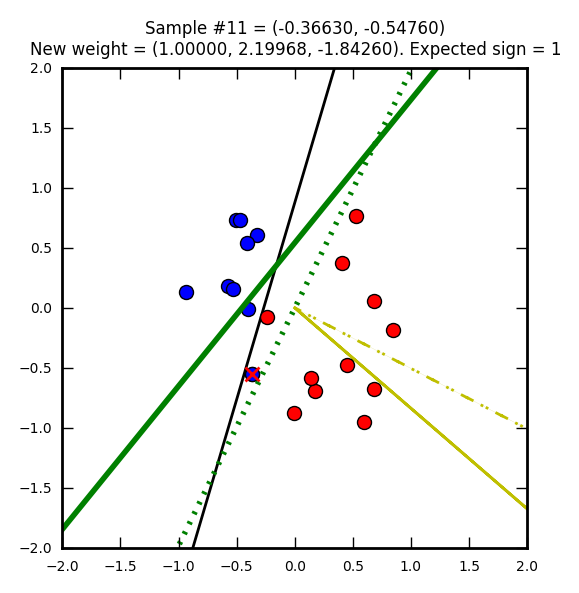
Ordonnée à l’origine = -(1 / -1.84260) = 0.5427… et abscisse = -(2.19968 / -1.84260) = 1.1937…
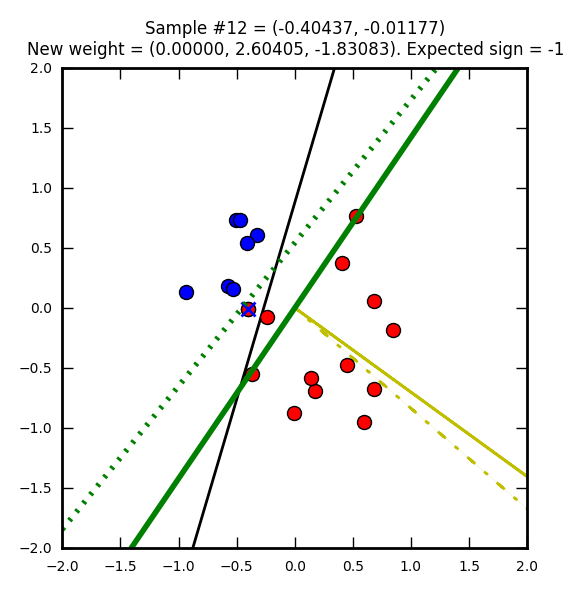
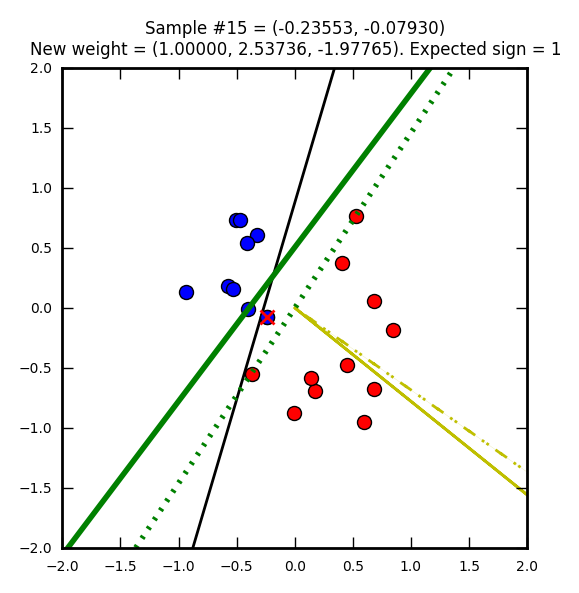
Et finit par trouver une solution valide :)
Pour obtenir une meilleure solution, il faudrait plus d’éléments en entrée ou faire des itérations supplémentaires pour ajuster plus finement les poids.
Published August 27 2016 at 15:32