
Introduction
Comment casser un captcha quand ce dernier est trop compliqué pour être simplement passé à un logiciel de reconnaissance de caractères comme Tesseract ?
Réponse : avec du machine learning bien sûr ! :)
Ici nous allons nous intéresser à un captcha de ce style trouvé sur le web :




Petit aparté : Des fois, il n’est nul besoin de casser le captcha en lui-même, car le mécanisme de session qui gravite autour est parfois mal implémenté.
Par exemple la solution du captcha à résoudre est généralement stockée dans la session (cookie côté serveur) or cette solution peut être générée lors du chargement de l’URL du captcha et non lors de la réception d’un code saisit, laissant alors au visiteur la possibilité de résoudre une première fois le captcha puis réutiliser sans cesse la même session sans jamais repasser par le rechargement du captcha (qui surviendrait automatiquement via un navigateur avec le chargement de la page html et des ressources liées, mais un robot n’a pas la même obligation).
Le présent article ne traite pas de ces bypass, mais bien de résoudre un captcha lorsque le mécanisme de session est correctement écrit et qu’il ne nous reste plus d’autres choix.
Caractéristiques du captcha
Avant de rentrer dans le vif du sujet, posons quelques minutes pour observer les points caractéristiques du captcha :
- il utilise des couleurs
- il y a des lettres, des traits et des cercles, tous de couleur unie
- il y a des pixels servant de bruit dans l’image
- les traits, cercles et pixels sont au-dessus des lettres
- il y a toujours 5 lettres
- certaines lettres sont absentes (
JQS) - plusieurs lettres peuvent se chevaucher
- les lettres touchent rarement le bord de l’image (elles sont relativement centrées)
- les lettres sont déformées
- certaines lettres ont des dimensions caractéristiques (le
Iet leYsont toujours très grands, leWet leMtoujours très larges) - le fond de l’image est uni (blanc)
Nettoyage du captcha
Afin de pouvoir reconnaître plus facilement où se situent les 5 lettres dans les images il est nécessaire de faire un nettoyage préalable.
L’objectif est ici de retirer le bruit superflu, à commencer par les pixels disséminés dans l’image.
En utilisant la librairie Pillow (The friendly PIL fork) nous allons scanner l’image à la recherche de zones de petites tailles dont les bords sont totalement blancs. On fera bien attention à ce que la taille maxi de ces zones ne puisse pas englober les plus petites lettres (comme le X).
L’algorithme est le suivant :
1
2
3
4
5
pour largeur_carré de 3 à 15:
pour chaque position (x, y) où il est possible de placer le carré dans l'image:
utiliser le carré comme un masque de sélection
si les bords de cette sélection sont blanc alors
remplir la zone carrée de blanc
Un problème demeure : les pixels isolés en bord de l’image. C’est un cas particulier qui nécessiterait des calculs supplémentaires pour vérifier que l’on ne va pas chercher des pixels en dehors des dimensions de l’image.
On peut contourner ce problème simplement en passant en blanc les pixels de bord de l’image puisque l’on sait qu’il est très rare que les lettres soient en contact avec le bord.
Cela sera réalisé par le code Python suivant :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#!/usr/bin/python3
from PIL import ImageFile
import sys
import logging
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
def is_white_bordered(corner1, corner2, image):
x_min, y_min = corner1
x_max, y_max = corner2
for x in range(x_min, x_max):
if image.getpixel((x, y_min)) != WHITE:
return False
if image.getpixel((x, y_max)) != WHITE:
return False
for y in range(y_min+1, y_max-1):
if image.getpixel((x_min, y)) != WHITE:
return False
if image.getpixel((x_max, y)) != WHITE:
return False
return True
with open(sys.argv[1], "rb") as fd:
p = ImageFile.Parser()
p.feed(fd.read())
image = p.close()
img2 = image.copy()
w, h = image.size
# On passe en blanc la bordure sur 1 pixel
for x in range(0, w):
img2.putpixel((x, 0), WHITE)
img2.putpixel((x, h-1), WHITE)
for y in range(0, h):
img2.putpixel((0, y), WHITE)
img2.putpixel((w-1, y), WHITE)
# A la recherche de zones bordées de blanc
for box_size in range(2, 15):
logging.debug("=== BOX SIZE = {} ===".format(box_size))
for x in range(w - box_size):
for y in range(h - box_size):
corner1 = (x, y)
corner2 = (x+box_size, y+box_size)
if is_white_bordered(corner1, corner2, img2):
for a in range(x, x+box_size):
for b in range(y, y+box_size):
img2.putpixel((a, b), WHITE)
img2.save(sys.argv[1].replace(".png", "_clean.png"))
Résultats obtenus :
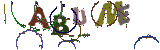
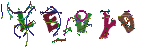


Not bad !
Déterminer les zones des différentes couleurs
À ce stade, on a des images avec moins d’éléments, mais il reste toujours des traits, des cercles ou des morceaux de cercles qui rendent difficile de deviner quelles zones sont importantes à garder.
Nous allons exploiter une des caractéristiques de l’image, à savoir que les éléments sont de couleur unie.
Pour chaque couleur présente dans l’image, nous allons calculer quelle zone de l’image (rectangle) elle couvre (du pixel le plus en haut à gauche à celui le plus bas à droite). Les dimensions de ces zones nous permettront déjà de discriminer certaines couleurs (par exemple le cercle sur l’image MYPOZ couvrant le M et le Y a des dimensions bien trop importante pour correspondre à une lettre).
On ne passera pas les couleurs anormales en blanc, mais on les retirera de la liste des couleurs intéressantes (pouvant correspondre aux lettres).
On va d’abord compter le nombre de pixels pour chaque couleur :
1
2
3
4
5
6
7
from collections import Counter
cnt = Counter()
for x in range(w):
for y in range(h):
pixel = img2.getpixel((x, y))
cnt[pixel] += 1
On calcule ensuite les zones des 15 couleurs les plus utilisées :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# Valeurs obtenues par tâtonnement
MAX_CHAR_WIDTH = 35
MAX_CHAR_HEIGHT = 32 # big ones are Y's
MIN_CHAR_WIDTH = 4 # big ones are Y's
MIN_SURFACE = 76 # example: vertical I
MAX_SURFACE = 910 # example: big M
# Nombre de pixels dans l'image
nb_pixels = w*h
color_boxes = {}
for color, count in cnt.most_common(15):
if color == WHITE:
continue
logging.debug("Color {} count for {:.3f}%".format(color, (count/nb_pixels)*100))
x_min = w
x_max = 0
y_min = h
y_max = 0
for x in range(0, w):
for y in range(0, h):
if img2.getpixel((x, y)) == color:
x_min = min(x_min, x)
y_min = min(y_min, y)
x_max = max(x_max, x)
y_max = max(y_max, y)
# Simple règle pour éviter les longs traits
if x_max - x_min > MAX_CHAR_WIDTH:
logging.debug("Color {} exceed width limit".format(color))
continue
if x_max - x_min < MIN_CHAR_WIDTH:
logging.debug("Color {} is not large enough".format(color))
continue
if y_max - y_min > MAX_CHAR_HEIGHT:
logging.debug("Color {} exceed height limit".format(color))
continue
surface = (y_max - y_min + 1) * (x_max - x_min + 1)
if surface < MIN_SURFACE:
logging.debug("Color {} doesn't take enough room (surface is {})".format(color, surface))
continue
color_boxes[color] = {"start": (x_min, y_min), "end": (x_max, y_max), "pixels": surface}
logging.debug("Added color {}".format(color))
Une couleur correspond-elle à un cercle ?
Une problématique que j’ai rencontrée est celle des cercles présents dans l’image : un cercle a parfois des dimensions dans les normes d’une lettre. On serait tenté de calculer le ratio que couvre la couleur du cercle dans sa zone carré correspondante. En effet, le trait des cercles étant toujours d’une largeur d’un seul pixel le ratio devrait être faible.
Malheureusement une lettre sera parfois tellement recouverte par les traits, bruit ou autre lettre que le ratio de couleur dans sa zone sera inférieure à celui d’un cercle !
J’ai dû m’adapter et écrire une fonction capable de déterminer si une couleur correspond à un cercle.
La solution : sachant que si le cercle est entier dans l’image alors sa zone sera carré et la moitié de la largeur du carré correspondra au rayon du cercle.
Dès lors il suffit de calculer la distance entre le centre du carré et chaque point qui constitue le cercle. Si toutes ces distances correspondent (à une marge d’erreur près) au rayon alors on est bien en présence d’un cercle. Si ne serais-ce qu’un seul pixel ne vérifie pas la règle alors on n’estime n’avoir pas affaire à un cercle.
Pour calculer la distance entre le centre du carré et un pixel du cercle, on utilisera simplement le théorème de Pythagore.
1
2
3
4
5
6
7
8
9
def is_circle(box, color):
r = min(box.width, box.height) / 2
for x in range(box.width):
for y in range(box.height):
if box.getpixel((x, y)) == color:
distance = sqrt((x-r)**2 + (y-r)**2)
if not r - 2 <= distance <= r + 2:
return False
return True
Et on appellera cette fonction depuis le code précédent de discrimination des couleurs :
1
2
3
if is_circle(img2.crop(box=(x_min, y_min, x_max, y_max)), color):
logging.debug("Color {} is a circle".format(color))
continue
Quelques statistiques sur les couleurs
Sur la liste de couleurs qu’il nous reste nous allons effectuer quelques calculs notamment pour déterminer le ratio de recouvrement de sa zone :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
for color in color_boxes:
x_min, y_min = color_boxes[color]["start"]
x_max, y_max = color_boxes[color]["end"]
color_count = 0
white_count = 0
for x in range(x_min, x_max+1):
for y in range(y_min, y_max+1):
pixel = img2.getpixel((x, y))
if pixel == WHITE:
white_count += 1
elif pixel == color:
color_count += 1
color_boxes[color]["count"] = color_count
color_boxes[color]["white"] = white_count
color_boxes[color]["color_percent"] = color_count / color_boxes[color]["pixels"]
color_boxes[color]["white_percent"] = white_count / color_boxes[color]["pixels"]
On ne gardera ensuite que zones avec une couleur à fort ratio en éliminant au passage les couleurs où l’on juge le blanc trop dominant (parfait pour les cercles tronqués) :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
i = 0
letters = {}
for color, infos in sorted(color_boxes.items(), key=lambda x: x[1]["color_percent"], reverse=True):
if i == 5:
break
if infos["white_percent"] > 0.7:
continue
i += 1
x_min, y_min = infos["start"]
x_max, y_max = infos["end"]
# On crée une nouvelle image à partir de la zone qui nous intéresse
letter = img2.crop(box=(x_min, y_min, x_max, y_max))
# --- snip ---
Nettoyer chaque lettre
À ce stade, on a déjà fait le plus gros du travail, car on considère avoir trouvé les zones des lettres et on pourrait s’arrêter là pour le prétraitement de l’image :




Les images ci-dessus ne montrent que les zones trouvées par l’algorithme par rapport à l’image original sans montrer les prétraitements.
Mais dans la zone de l’image va se retrouver par exemple des morceaux de traits qui passaient par là où des pixels de bruit qui n’ont pas pu être retirés par le premier traitement.
On connait la couleur de la lettre supposée alors on va observer le placement des pixels de couleur différente. Si le pixel est entouré par la couleur dominante alors cela signifie qu’il est posé dessus et on peut le remplacer par la couleur dominante.
S’il est entouré par deux pixels de la couleur dominante, on suppose qu’il est en bordure de la lettre, auquel cas, on peut le conserver.
Sinon il s’agit vraisemblablement d’un morceau de trait sans contact direct avec la lettre, auquel cas, on le remplace en blanc.
Pour cela plusieurs fonctions ont été nécessaires :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from itertools import product
def surrounding_coordinates(x, y, size):
w, h = size
arround = [x for x in product([-1, 0, 1], [-1, 0, 1]) if x != (0, 0)]
for a, b in arround:
x1, y1 = (x+a), (y+b)
if 0 <= x1 < w and 0 <= y1 < h:
yield x1, y1
def surrounding_colors(x, y, image):
for x1, y1 in surrounding_coordinates(x, y, image.size):
yield image.getpixel((x1, y1))
def is_surrounded_by(x, y, image, color, threshold=2):
count = 0
for neighbor in surrounding_colors(x, y, image):
if neighbor == color:
count += 1
if count >= threshold:
return True
return False
On nettoiera l’image de cette manière :
1
2
3
4
5
6
7
8
for x in range(letter.width):
for y in range(letter.height):
if letter.getpixel((x, y)) == color:
# Color of the letter : keep it
continue
if not is_surrounded_by(x, y, letter, color):
letter.putpixel((x, y), WHITE)
Convertir les lettres en une matrice de niveaux de gris
Maintenant que l’on a des lettres propres en couleur, il faut pouvoir les passer dans une forme compréhensible par un algorithme de machine learning.
Jusqu’à présent on a travaillé sur des triplets RVB. Le passage en niveaux de gris permettra d’avoir un chiffre (de 0 à 255) pour chaque pixel.
On redimensionne aussi les zones des lettres à une dimension fixe, d’abord parce que l’on ne peut comparer que ce qui est comparable et ensuite parce que cela réduit la taille de la matrice et donc les calculs pour l’algorithme de machine learning.
J’ai choisi de redimensionner en 8x8. J’ajoute aussi une ligne à cette matrice pour y rajouter les dimensions originales de la zone de la lettre ainsi que le ratio hauteur/largeur, car ce sont des informations que je juge pertinentes pour classifier certaines lettres (I, Y, M, W et X par exemple).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
letter = letter.resize((8, 8), resample=BICUBIC).convert("L")
lines = []
for y in range(8):
rows = []
for x in range(8):
rows.append(letter.getpixel((x, y)))
lines.append(rows)
# Ajout des dimensions de la box pour les prendre en compte en tant que features + valeurs nulles
# pour avoir une dimension de 8 pour ravel()
width = x_max - x_min
height = y_max - y_min
lines.append([width, height, width/height, 0, 0, 0, 0, 0])
letters[x_min] = np.array(lines)
Entraîner le classifieur
C’est bien beau de savoir où sont situées telles ou telle lettre, encore faut-il indiquer au classifieur quelle lettre se trouve dans chaque zone pour qu’il puisse apprendre.
C’est la partie la moins attrayante, car il va falloir résoudre à la mano le plus de captchas possible si on veut que le classifieur soit efficace.
Une fois que l’on aura assemblé une bonne quantité de captchas résolus (on stockera par exemple chaque image en donnant comme nom de fichier la solution du captcha) il faut passer en revue tous les samples et vérifier que les lettres sont dans les bonnes zones.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from os.path import basename
learning_dict[base] = {}
base = basename(imagepath)
image.resize((320, 100)).show()
match = input("match (y/n)? ").strip()
if match == "y":
learning_dict[base]["letters"] = []
learning_dict[base]["targets"] = []
for i, k in enumerate(sorted(letters.keys())):
# La méthode ravel() de numpy aplatit notre matrice multi-dimension en un vecteur
learning_dict[base]["letters"].append(letters[k].ravel())
learning_dict[base]["targets"].append(base[i])
Générer le modèle
On aura recours à la librairie scikit-learn et dans le code ci-dessous à un classifieur LinearSVC.
Les classifieurs s’entraînent via la méthode fit() et prennent en entrée la liste des matrices (nos pixels en niveau de gris + les dimensions et ratio) ainsi que les données de sortie attendues.
On utilisera joblib pour dumper le modèle dans un fichier pkl.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from sklearn.externals import joblib
from sklearn import svm
clf = svm.LinearSVC()
letters = []
targets = []
for filename, captcha in learning_dict.items():
if "letters" in captcha:
if filename[:5] != ''.join(captcha["targets"]):
print("Error with captcha {}".format(filename))
exit()
for letter in captcha["letters"]:
letters.append(letter)
for target in captcha["targets"]:
targets.append(target)
clf.fit(letters, targets)
joblib.dump(clf, "model.pkl")
Prédire les lettres
La prédiction consiste à récupérer les données d’entrées extraites d’une image (matrice de chaque lettre) et à les passer à la méthode predict() du classifieur.
Ce dernier nous renverra alors une liste des valeurs prédites pour chaque matrice donnée en entrée.
J’ai choisi d’appeler predict() pour chaque matrice, ce qui est sans doute anti-performant, mais négligeable à la vue du temps imparti pour donner une valeur pour le captcha.
1
2
3
result = ""
for i, k in enumerate(sorted(letters.keys())):
result += clf.predict([letters[k].ravel()])[0]
Les images de l’article provenaient des samples de test et n’ont pas été utilisées pour l’entrainement. Le résultat est bon pour ces images.
1
2
$ python crack.py test/abume.png
abume
SUCCESS !! Mais les résultats ne sont pas parfaits non plus.
J’ai testé plusieurs classifieurs et eu des résultats et performances différentes :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
LinearSVC
==== STATS ====
Good: 63
Bad: 33
Errors: 4
Time: 0:06:08.313932
DecisionTreeClassifier
==== STATS ====
Good: 45
Bad: 51
Errors: 4
Time: 0:04:51.826667
GaussianNB
==== STATS ====
Good: 59
Bad: 37
Errors: 4
Time: 0:04:11.536753
Dans le cas d’un décodage de captcha le nombre de bons résultats prime sur la durée d’exécution. Avec LinearSVC sur 100 images, on obtient 63 captchas décodés avec succès, 4 captchas où il n’a pas été possible de déterminer toutes les zones de lettres (souvent il s’agit de captcha où même un humain rencontrerait des difficultés) et 33 captchas où l’on avait trouvé les bonnes zones, mais où on a prédit au moins une mauvaise lettre.
Quelques pistes d’amélioration
Parmi les idées visant à améliorer le taux de prédiction des caractères on notera :
- augmenter le nombre de samples lors de l’entrainement, c’est toujours ça de pris.
- augmenter le nombre de targets pour limiter les indécisions de l’algorithme. La lettre
Tse retrouve parfois droite, parfois tournée sur la droite, parfois sur la gauche, ce qui provoque des détections à tort pour la lettreX. On pourrait différencier les trois types de T lors de l’apprentissage pour que le classifieur soit plus assuré quant aux résultats. - nettoyer directement les bords droit, gauche et bas de l’image où l’on ne trouve généralement pas de lettres.
- détecter les arcs de cercle.
- utiliser des losanges (ou triangles) en plus des carrés comme forme de sélection pour trouver les pixels de bruit
- chercher différemment les zones intéressantes (par exemple les zones avec la plus forte densité de couleurs)
- utiliser OpenCV : cette librairie a des fonctionnalités plus évoluées que Pillow qui devraient faciliter et améliorer les différentes étapes
Published November 17 2020 at 13:50