
Quand on compile un code source (par exemple en langage C) pour en faire un fichier exécutable, le code subit différentes transformations.
Le code va notamment être transformé en code langage assembleur, un langage de bas niveau qui effectue des opérations simples sur les données en mémoire.
Ce code est ensuite transformé en langage machine en utilisant une sorte de table de correspondance définie par le processeur.
Chaque instruction est caractérisée par un numéro appelé opcode ou code opération. Ainsi, une instruction est simplement un groupement de bits – différentes combinaisons correspondent à différentes commandes à la machine. La traduction la plus lisible du langage machine est appelée langage assembleur, qui est une traduction de chaque groupe de bits de l’instruction. Par exemple, pour les ordinateurs d’architecture x86, l’opcode 0x6A correspond à l’instruction push et l’opcode 0x74 à je (jump if equal).
Source: Wikipedia
Comme ces instructions ne font pas toutes la même taille et ne reçoivent pas le même nombre d’arguments, on ne peut pas lire le code binaire en le prenant n’importe où. Il faut partir du début du code et le lire linéairement, instructions après instructions.
Évidemment le langage assembleur permet de faire des sauts dans le code et lors de l’exécution du binaire, le processeur n’aura aucun mal à suivre les instructions. En revanche pour un logiciel désassembleur il est difficile d’analyser tous les branchements possibles et il va donc faire une lecture linéaire du code.
Une technique utilisée pour rendre l’analyse de code plus difficile consiste à fausser cette lecture linéaire par exemple un plaçant un saut inconditionnel immédiatement suivi de données aléatoires qui vont casser la séquence d’instructions.
Le processeur ne voit rien de choquant puisqu’en sautant sur le bon code, il recale convenablement les instructions mais un désassembleur s’y cassera souvent les dents.
Pour notre exemple, on va prendre un exemple très simple :
1
2
3
4
5
6
7
8
9
10
11
12
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int x;
x=3;
__asm__("nop\n\t");
x=8;
printf("%d\n",x);
return 0;
}
Le code déclare une variable x et y assigne la valeur 3. x devient ensuite 8 et la valeur de x est affichée (8). Au milieu, on a implicitement inséré des nops. Le nop est une instruction qui ne fait rien… si ce n’est prendre de la place dans le code (1 octet).
Le code généré par gcc est le suivant :
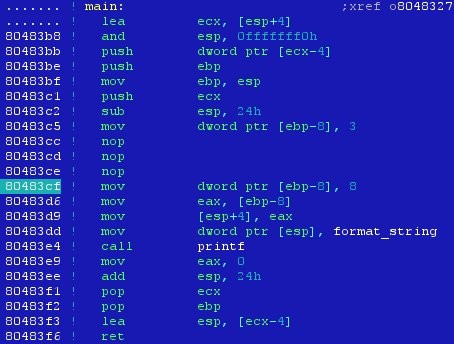
On voit clairement qu’à l’adresse 0x80483cf notre variable locale se voit affecter la valeur 8.
Notre objectif va être de dissimuler cette affectation pour qu’une analyse ne permette pas de déterminer la valeur affichée par printf à la fin.
On a seulement 3 octets (correspondants aux nops) pour insérer notre saut (jmp) ainsi qu’un octet pour décaler les instructions.
Une instruction jmp prend comme argument l’adresse vers laquelle elle doit se rendre. L’opcode associé peut varier selon que l’adresse soit relative ou absolue.
Exemple de jmp avec adresse absolue :
1
80482e8: ff 25 04 a0 04 08 jmp *0x804a004
Exemple de code qui utilise des adresses relatives :
1
2
3
4
5
6
7
8
9
10
11
804836d: 74 0c je 804837b <__do_global_dtors_aux+0x1b>
804836f: eb 1c jmp 804838d <__do_global_dtors_aux+0x2d>
8048371: 83 c0 04 add $0x4,%eax
8048374: a3 14 a0 04 08 mov %eax,0x804a014
8048379: ff d2 call *%edx
804837b: a1 14 a0 04 08 mov 0x804a014,%eax
8048380: 8b 10 mov (%eax),%edx
8048382: 85 d2 test %edx,%edx
8048384: 75 eb jne 8048371 <__do_global_dtors_aux+0x11>
8048386: c6 05 18 a0 04 08 01 movb $0x1,0x804a018
804838d: c9 leave
Dans le cas des adresses relatives, l’opcode tient sur un octet et l’argument sur un octet aussi. C’est donc parfait dans notre cas.
Le jmp dans le code ci-dessus fait un saut de 0x1c. Ça correspond à l’adresse destination - l’adresse suivant immédiatement le jmp = 804838d - 8048371
Dans notre cas, après insertion du jump, il ne nous restera qu’un octet à sauter. Notre code pour le saut sera donc eb 01. L’opcode à insérer sur le troisième octet doit correspondre au début d’une instruction tenant sur plusieurs octets afin de s’assurer que la lecture linéaire du code va être cassée.
Un 83 qui correspond à l’instruction add convient parfaitement et va prendre la suite de notre code comme argument pour une addition.
Sous HT Editor on fait un F4 pour passer en mode édition. On se place sur les opcodes et on tape eb01 puis 83.
On repasse en mode view avec F4 et on valide les changements. On sauve ensuite avec F2.
Le code est alors le suivant :
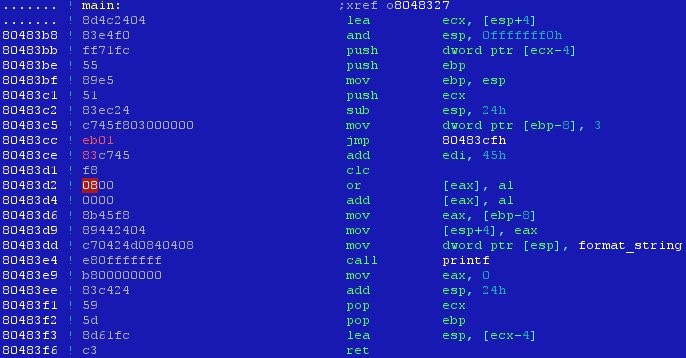
On voit bien notre valeur 8 dans le code hexadécimal mais celle-ci est interprétée comme une instruction or. L’affectation de notre variable x à la valeur 8 n’est plus visible.
À noter que le hazard a fait que notre code s’est recalé de façon à ce que le printf soit toujours visible.
Des désassembleurs comme objdump, ndisasm et même HT Editor s’y cassent maintenant les dents. La seule solution est de leur dire de prendre le désassemblage directement à l’adresse spécifiée par le jump :
1
2
objdump -d --start-address=0x080483cf /tmp/obfusc | head
ndisasm -e 975 -b 32 /tmp/obfusc | head
Notre exemple n’est pas très discret puisque le jmp tombe en plein milieu d’une instruction add.
En plus des désassembleurs plus évolués parviennent à détecter ces méthodes.
Published January 09 2011 at 13:04