
Après le cookie dumper, voici le cache dumper qui comme son nom l’indique permet d’analyser le cache du navigateur Opera.
Sous Opera, on trouve deux dossiers de cache.
L’un s’appelle opcache et sert uniquement aux sites liés à Opera lui-même comme les requêtes à destination du sitecheck (système anti-fishing du navigateur), les requêtes vers DragonFly (API pour développeurs web intégré au navigateur) et requêtes vers les autres sous-domaines d’Opera.
Le second dossier est le dossier cache4 et conserve la grande majorité des fichiers gardés en mémoire par Opera.
Dans les deux cas, les fichiers mis en cache sont renommés sous la forme oprXXXXX (où XXXXX est composé de chiffres et lettres majuscules) et un fichier nommé dcache4.url présent dans le même dossier est un index qui garde les informations spécifiques à chacun des fichiers.
Il est important de noter que si vous avez coché Empty on exit dans les préférences, Opera n’utilisera pas le fichier d’index, mais stockera tout de même des fichiers en cache. Les associations entre les fichiers présents dans le cache et les sites Internet correspondants sont alors impossibles à déterminer (Opera garde ces associations en mémoire, mais ne les écrit pas sur le disque).
Comme pour l’analyse du fichier cookies4.dat la dernière fois, j’ai rencontré certains tags non documentés dans la documentation officielle.
On peut par exemple trouver le tag 0x00 dont la valeur est toujours la même (0x8000000B) et qui ne semble pas avoir de signification.
Il y a un tag 0x2e qui représente la langue utilisée pour un fichier de cache donné (par exemple fr_FR).
Tout aussi énigmatique, le tag 0x3a qui me semble lié à l’entête HTTP Age reçu comme réponse des serveurs. Un entête qui m’était inconnu et qui m’a fait penser au ver Conficker qui se base sur un autre entête HTTP pour déterminer la date et l’heure actuelle. Le header Age semble renvoyer une valeur numérique dans un intervalle prédéfini et augmente avec le temps… ça pourrait être pratique comme moyen de trouver un nombre aléatoire.
Enfin on trouve des tags qui permettent au navigateur d’intégrer directement des entêtes HTTP et leurs valeurs dans l’index de cache. Le tag racine est le 0x3b, suivi par le 0x3c. Le 0x3d défini le nom de l’entête et le tag 0x3e sa valeur.
Le programme que j’ai fait prend comme argument le chemin vers le fichier dcache4.url ainsi qu’un dossier où sera placée l’analyse du cache. Si ce dernier dossier n’existe pas, il est créé automatiquement.
Pour chaque fichier référencé dans le cache, le programme détermine sa nature à partir de sa valeur mime (image/png, text/html, application/x-javascript, etc) et s’il est compressé (Content-Encoding défini par le tag 0x20). Si c’est le cas, le fichier est décompressé (si possible, car certains fichiers sont compressés en deflate et non par gzip) avant d’être copiée dans le dossier de destination.
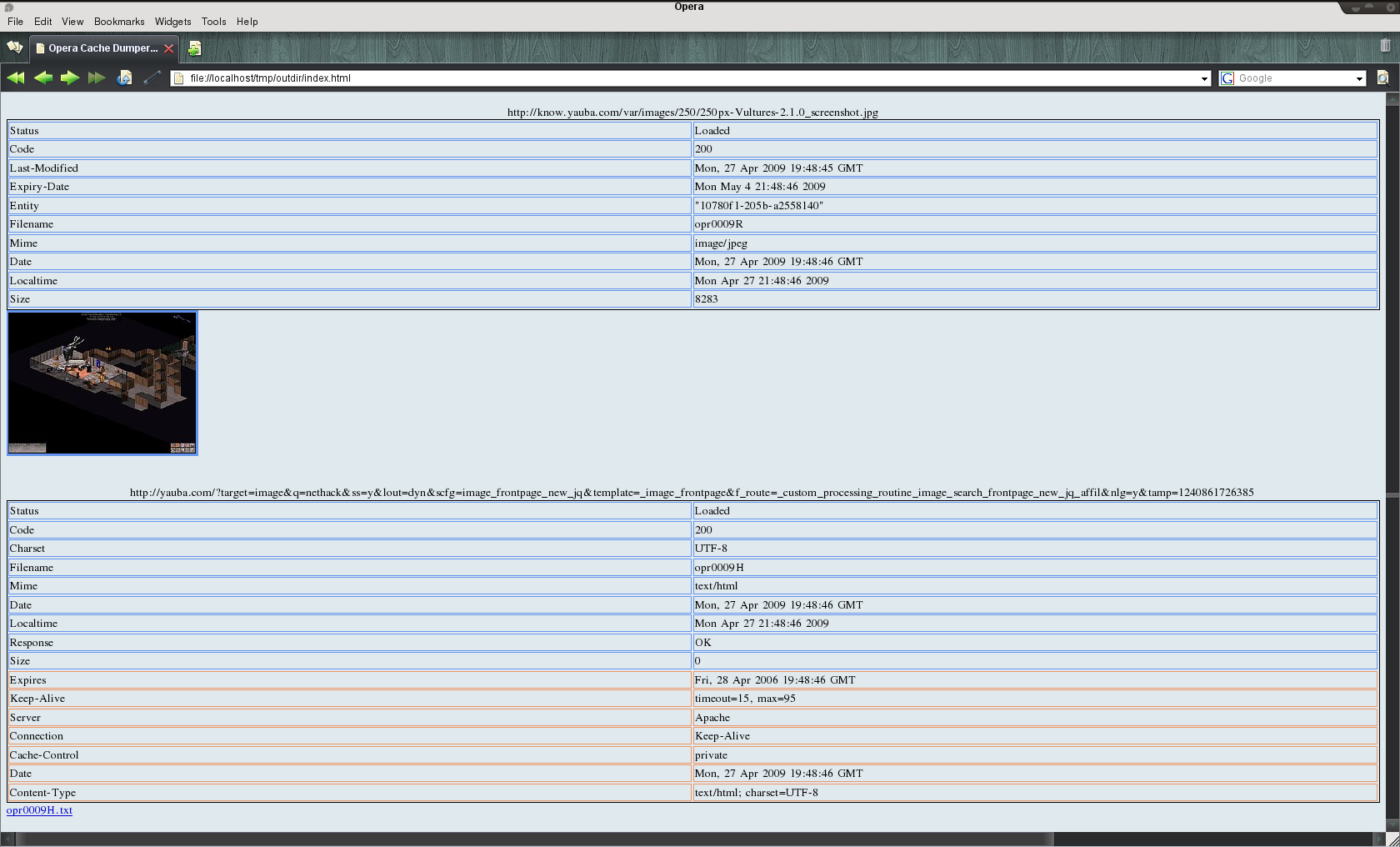
Le programme génère ensuite un fichier HTML qui permet d’afficher facilement l’ensemble des fichiers du cache et leurs métadonnées associées. S’il s’agit d’une image, elle est affichée. Sinon un lien permet d’accéder à la ressource. Les javascripts et codes html ont l’extension txt pour éviter qu’ils soient interprétés.
Comme les descriptions et les images sont chargées dans la même page HTML, ça peut prendre du temps à charger en fonction du cache analysé (il faut mieux un système avec une bonne mémoire)
Le résultat ressemble à ça (extrait) :
Le code est ici : opcadump.py.
Published January 11 2011 at 12:02