
Après quelques migraines sur les spécifications des codes QR voici finalement mon writeup pour la partie Random du CySCA 2014.
Pulp Fiction (120 points)
RL Forensics Inc. has contracted Fortcerts to recover information stored in this bitmap. Both companies failed to recover the information but they identified that it was encrypted with AES-ECB. Can you recover the information in the encrypted bitmap?
ECB (Electronic codebook) est un mode d’opération pour la cryptographie consistant à découper un message en blocs et à effectuer le chiffrement de chaque bloc avec la même clé sans réaliser d’opérations de chaînage.
L’inconvénient de ce mode c’est qu’il est alors très facile de discerner les répétitions dans le message chiffré (par exemple une zone remplie d’octets nuls) qui permettent de deviner la taille de la clé de chiffrement voire se faire une idée sur la nature du fichier (format, etc).
Un mode à éviter dont la faiblesse est souvent illustrée à l’aide d’images : au lieu d’obtenir du “bruit” une image chiffrée en ECB laissera distinguer les formes de l’image originale.
Pour résoudre l’exercice je ne me suis donc pas tourné vers un quelconque logiciel cryptographique mais vers GIMP.
Pour celà il suffit d’ouvrir le fichier chiffré comme s’il s’agissait d’une image brute (GIMP -> open as raw) :
Comme les entêtes sont inconnus on doit spécifier nous même la longueur et largeur de l’image :
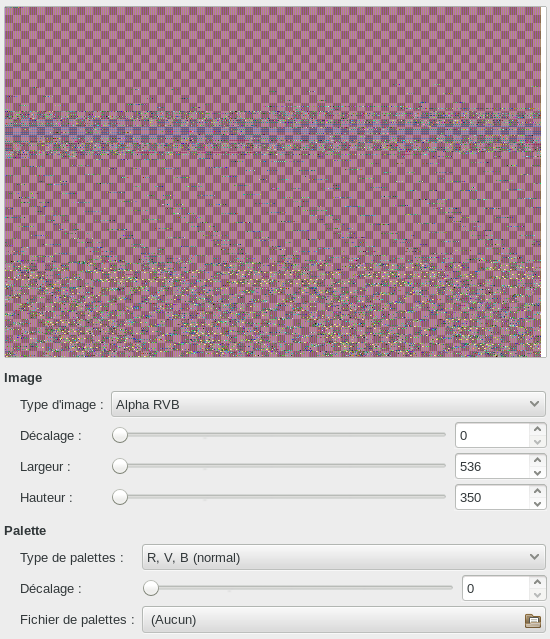
Par tâtonnements on trouve des paramètres valides :

Et après quelques retouches artistiques :

Le flag est BoxingDesktopGutter798.
Spanish Trout (200 points)
Fortcerts has been hired by Mad Programming Skillz Pty. Ltd. to perform source code review to find vulnerabilities in the password checking algorithm that they use in many of their products. Fortcerts does not have the expertise to do c code auditing so they have asked you to take a look. Try find any vulnerabilities and capture the flag to demonstrate that an attacker could exploit the identified vulnerabilities. The test code is running at 192.168.1.64:12345
On a droit à un petit extrait de code C qui utilise l’algorithme SHA1 via la librairie openssl :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
void handle_client(int client_socket)
{
unsigned char hash[SHA_DIGEST_LENGTH];
unsigned char secret_hash[SHA_DIGEST_LENGTH];
char secret_key[256];
char data[256] = {0};
sendline(client_socket, "Welcome to the SHA password oracle.\n");
sendline(client_socket, "Enter your password:");
if (recvline(client_socket, data, sizeof(data)) == -1)
return;
// SHA the entered password
SHA1(data, strlen(data), hash);
// Load and SHA the secret key
size_t secret_length = load_flag(secret_key, sizeof(secret_key));
SHA1(secret_key, secret_length, secret_hash);
// Compare the two hashes and determine if the password is correct
if (strncmp(secret_hash, hash, SHA_DIGEST_LENGTH) == 0) {
char buf[512] = {0};
snprintf(buf, sizeof(buf)-1, "Congratulations: The key is %s", secret_key);
sendline(client_socket, buf);
} else {
char secret_hash_str[80] = {0};
char hash_str[80] = {0};
char buf[512] = {0};
bytes_to_string((unsigned char*)secret_hash, secret_hash_str, sizeof(secret_hash_str));
bytes_to_string((unsigned char*)hash, hash_str, sizeof(hash_str));
snprintf(buf, sizeof(buf)-1, "Your hash %s does not match the secret hash %s", hash_str, secret_hash_str);
sendline(client_socket, buf);
}
close(client_socket);
}
Si l’on rentre un mot de passe invalide le hash à obtenir est affiché comme indiqué dans la source :
1
2
3
4
5
6
7
8
9
$ ncat 192.168.1.64 12345 -v
Ncat: Version 6.01 ( http://nmap.org/ncat )
Ncat: Connected to 192.168.1.64:12345.
Welcome to the SHA password oracle.
Enter your password:
test
Your hash A94A8FE5CCB19BA61C4C0873D391E987982FBBD3 does not match the secret hash 3BFC00848D4F990A3D3C3131A17B6092F89DDAE4
Ncat: 5 bytes sent, 181 bytes received in 1.87 seconds.
En lisant le code C j’ai rapidement tilté sur l’utilisation de strncmp (une fonction destinée à des chaînes de caractère) pour comparer des hashs bruts générés par la fonction SHA1.
En particulier le hash pour lequel on doit trouver le mot de passe contient un octet nul (3ème octet).
La page de manuel de strncmp n’est pas vraiment exhaustive sur le sujet mais ça semble évident que la comparaison s’arrête à l’octet nul si rencontré avant la taille passée en argument.
Par conséquent j’ai écrit un script qui cherche un hash commençant par 3bfc00 (je n’ai testé que les chiffres) :
1
2
3
4
5
from hashlib import sha1
for i in range(0, 100000000):
if sha1(str(i)).hexdigest().startswith("3bfc00"):
print "Found match with", i
On finit par trouver un mot de passe qui correspond à nos attentes :
1
2
3
4
5
6
7
8
9
$ ncat 192.168.1.64 12345 -v
Ncat: Version 6.01 ( http://nmap.org/ncat )
Ncat: Connected to 192.168.1.64:12345.
Welcome to the SHA password oracle.
Enter your password:
39553410
Congratulations: The key is RetroFarmingAssault570
Ncat: 9 bytes sent, 109 bytes received in 1.25 seconds.
Reed Between The Lines (280 points)
In an RL Forensics Inc. case contracted out to Fortcerts, an image has been found on a suspects computer. Analysts believe there is corrupted information secretly hidden in the image. As a “computer expert” they want you to recover the data from this image.
Tout ce que l’on a à notre disposition c’est une photo d’un bâtiment blanc de l’autre côté d’un fleuve (l’équivalent australien de la Maison Blanche ? un parlement ?).
On note aussi que sur cette photo il y a à droite une poubelle sur laquelle un QR code a été collé mais ce dernier est en partie recouvert par du scotch noir.
Le titre des exercices donne généralement un indice sur ce qu’il faut faire. Ici on peut remarquer la présence de “Reed” (qui signifie roseau) au lieu de “Read”.
| Roseau entre les lignes… Mouais : | Faute de connaissances sur le sujet je n’ai pas capté sur le coup mais j’y reviendrais :) |
Premier réflexe : regarder les données EXIF avec différents outils… et là rien d’intéressant :
1
2
3
4
5
6
7
8
9
10
11
Marqueurs EXIF dans'image_cysca.jpg' (ordre des octets 'Intel') :
--------------------+----------------------------------------------------------
Marqueur |Valeur
--------------------+----------------------------------------------------------
X-Resolution |72
Y-Resolution |72
Unité de la résoluti|pouces
Version d'exif |Version d'exif 2.1
FlashPixVersion |FlashPix Version 1.0
Espace des couleurs |Non calibré
--------------------+----------------------------------------------------------
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
$ exiftool image_cysca.jpg
ExifTool Version Number : 9.70
File Name : image_cysca.jpg
Directory : .
File Size : 3.0 MB
File Modification Date/Time : 2015:05:16 17:51:41+02:00
File Access Date/Time : 2015:05:16 17:51:50+02:00
File Inode Change Date/Time : 2015:05:16 17:51:41+02:00
File Permissions : rw-r-----
File Type : JPEG
MIME Type : image/jpeg
Exif Byte Order : Little-endian (Intel, II)
Quality : 100%
IPTC Digest : 00000000000000000000000000000000
DCT Encode Version : 100
APP14 Flags 0 : [14], Encoded with Blend=1 downsampling
APP14 Flags 1 : (none)
Color Transform : YCbCr
Image Width : 3790
Image Height : 1365
Encoding Process : Baseline DCT, Huffman coding
Bits Per Sample : 8
Color Components : 3
Y Cb Cr Sub Sampling : YCbCr4:4:4 (1 1)
Image Size : 3790x1365
En me rencardant sur JPEG j’ai découvert qu’il ne s’agissait pas d’un format de fichier mais d’une norme de compression…
J’ai eu recours à des outils comme JPEGsnoop et picojpeg (deux outils qui fonctionnent avec Wine sous Linux) pour extraire les données compressées de l’image.
Seulement… rien d’intéressant à trouver :(
J’ai préféré jeter un œil aux quelques indices officiels laissés aux participants :
Premier indice :
1
2
3
Tip #1. No stego
Tip #2. M (i+j)%3
Tip #3. Length=32,Encoding=byte
Pas de stéganographie… bon. Quand au reste… hein ?
Regardons les indices restants :
No need to solve reed solomon polynomials for this one. A phone and spreadsheet is all you need.
Those that skimmed the spec, the mask is used for decoding.
Le “Reed” faisait donc référence au code Reed-Solomon qui est une méthode de correction d’erreur qui se base sur des notions mathématiques comme les corps fini (champs de Galois) et la division de polynômes.
Et ce code est justement utilisé par les codes QR pour permettre de retrouver des données sur des codes QR endommagés :
Almost all two-dimensional bar codes such as PDF-417, MaxiCode, Datamatrix, QR Code, and Aztec Code use Reed–Solomon error correction to allow correct reading even if a portion of the bar code is damaged. When the bar code scanner cannot recognize a bar code symbol, it will treat it as an erasure.
Les plus curieux pourront aller sur cet article pour tout savoir sur le sujet : Reed–Solomon codes for coders
On va donc s’attarder sur ce fichu code barre que voici (je n’ai pas inclus l’image dans sa totalité en raison de sa taille) :

Bien sûr ça ne scanne pas avec les lecteurs QR de smartphones. La première chose que j’ai faite c’est recréer le QR code (du moins ce qu’on peut avoir) dans une image GIMP de 29*29 pixels en l’ayant remise dans le sens officiel de la lecture.
J’ai aussi ajouté le finder caché (voir plus loin pour les explications) :

Bien sûr ça ne scanne toujours pas :p
Mais au fait c’est quoi un code QR ? Je vais expliquer ici une bonne partie de leur structure mais je recommande aussi la lecture de la page Wikipedia et du tutoriel de Thonky.
Un code QR c’est un code barre à deux dimensions. Il est carré et ses dimensions changent en fonction de la version du code QR utilisé.
Ainsi en version 1 la taille est de 21 modules sur 21. En version 2 il est de 25*25 et en version 3 de 29*29 (on ajoute 4 modules pour chaque incrément de version), etc.
Un module c’est la plus petite unité graphique du code QR, c’est à dire un petit carré soit blanc soit noir. J’aurais pu parler de pixel et tout le monde comprendrait mais ce ne serait pas syntaxiquement correct car un pixel est une unité relative à la résolution de l’image et que la largeur d’un module fait généralement plusieurs pixels.
Format d’un code QR
Voici une image de ma création représentant la structure d’un code QR (ici en version 3 qui est la version du challenge).
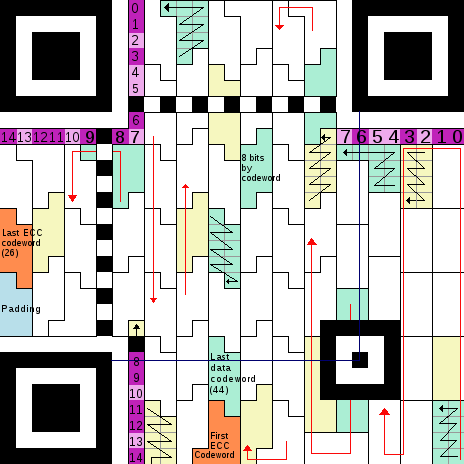
Sur 3 coins du code QR on trouve des “finders”, ce sont des carrés qui permettent aux scanneurs de code barre de délimiter la zone du code QR et déterminer son orientation.
Un finder est un carré noir de 3*3 modules, entouré d’une zone blanche puis d’un rectangle noir.
Les finders sont bordés par une zone blanche appelée “separator”.
Entre ces “finders” ont trouve deux “timing”. Ce sont deux lignes (l’une verticale, l’autre horizontale) qui alternent couleur noir et blanc.
Ajouté à cela on trouve un “dark module” situé à droite du finder bas-gauche.
De la version 2 à la version 6 on trouve aussi un “alignment pattern” (à droite sur l’image). C’est un module noir entouré d’une zone blanche puis d’un rectangle noir comme un finder mais sans separator. Comme son nom l’indique il permet au scanneur de code barre de déterminer l’alignement de l’image (il faut bien voir que le scanneur ne sera pas forcément pile en face et parallèle au code QR lors du scan).
Dans les versions 7 et supérieures plusieurs patrons d’alignement sont présents. Il n’y en a pas dans la version 1.
En violet sur l’image se trouvent les bits décrivant le format du code QR. Il s’agit de 14 bits qui se trouvent dans le coin haut-gauche mais qui sont aussi présents à deux autres coins séparément. Cette redondance est bien sûr destinée à la lecture de codes endommagés.
Un module noir correspond à un 1 et un module blanc à un 0. Les bits de format ne sont pas placés tels quels mais XORés avec la valeur 101010000010010.
On a en réalité dans l’exemple l’information de format 000111101011001 (car 101101101001011 ^ 101010000010010 = 000111101011001).
Sur l’image le module numéroté 0 est le bit de poids faible et le 14ème celui de poids fort.
Les deux premiers bits (de poids fort) décrivent le niveau de correction d’erreur. Les valeurs possibles sont les suivantes :
1
levels = {0: "Medium", 1: "Low", 2: "High", 3: "Quality"}
Ici le niveau de correction d’erreur (donc de récupération possible de données si le code est endommagé) est medium soit 15% de données récupérables (7 pour Low, 25 pour Quality/Quartile, 30 pour High).
Viennent ensuite les bits de masque. Leur valeur définissent un algorithme simple pour savoir si un bit de donnée (tout module d’une zone que l’on a pas encore vu) doit être lu normalement (0 pour blanc, 1 pour noir) ou l’inverse.
Il tient sur 3 bits. Ici il vaut 3 (011) ce qui correspond à l’algorithme de masque (i + j) % 3 == 0.
Les variables i et j représentent simplement les coordonnées d’un module. Ces coordonnées commencent à 0,0 dans le coin haut-gauche (et vont jusqu’à 28,28 en bas à droite pour la version 3).
Ainsi si on a un module noir en 10,2 il ne vaudra pas 1 mais 0 car (10 + 2) % 3 == 0 (valeur inversée car la formule du masque se vérifie).
L’objectif de ce masque est d’éviter de trouver de grandes zones blanches ou noires dans le code QR et de faciliter le travail du scanneur. Ca peut aussi permettre d’éviter de se retrouver avec un alignment pattern qui n’en est pas un !
Il y a 8 formules de masque différentes. Les logiciels de génération de code QR choisissent automatiquement la formule qu’ils considèrent la plus adaptée.
A ma connaissances aucun encodeur ne laisse l’utilisateur choisir lui même son masque… ce qui serait pourtant bien pratique pour du déboguage.
L’intégration des données
Comme indiqué plus haut, toutes les autres zones de l’image correspondent à des données et sont soumises au masquage.
Les données sont intégrées dans l’image sous la forme de “codewords”. Un codeword est un bloc sécable pas forcément rectangulaire de 8 modules (donc correspond à un octet).
Ces codewords se lisent en partant du coin bas-droit et continuent en zig-zag vers le haut puis le bas puis le haut etc et de droite à gauche comme illustré par les flèches rouges sur l’image.
Les premiers codewords sont ceux qui contiennent le message. Ceux de la fin sont les coderwords de correction d’erreur.
Un codeword est sécable ce qui veut dire que lorsqu’il croise un timing ou le patron d’alignement il va stoper sa course pour la reprendre de l’autre côté de l’obstacle.
Un codeword n’est pas forcément carré. Il s’adapte aussi selon les obstacles et s’il n’a pas la place de mettre deux modules sur une même ligne horizontale ce n’est pas grave, il continue en suivant la règle de remplissage des codewords (vue plus tôt) ainsi que celle des modules dans le codeword.
Les modules (c’est à dire les bits) remplissent un codeword en cherchant toujours à commencer par le côté droit puis le gauche de la même ligne puis le droit de la ligne suivante etc.
Cela est illustré par les flèches noires dans l’image.
Le sens vertical de remplissage des modules suit le sens vertical du placement des codewords (si un codeword va vers le bas, les modules aussi).
Sur un codeword qui s’étale sur deux colonnes, les modules changent de direction verticale à partir du moment où ils se retrouvent sur l’autre colonne. La règle est toujours de commencer par le module le plus à droite (ce qui s’accorde avec le fait de se rendre vers la gauche de l’image).
Une fois qu’on a chopé le truc on peut traiter n’importe quelle configuration de remplissage.
Les 4 premiers modules de l’image définissent l’encodage des données dans les codewords. Il y a 5 modes existants : numérique, alphanumérique, byte (octet), kanji et ECI.
Il va de soit que si vous ne voulez placer que des chiffres dans le code QR vous gagnerez de la place en utilisant le mode numérique et obtiendrez un QR code plus petit (sinon utilisez un encodage moins adapté avec un numéro de version plus grand).
On trouve les valeurs des différents modes ici : Thonky : Data Encoding
Les 8 modules qui suivent correspondent à la longueur du message en codewords.
Le fait d’utiliser un couple version QR / niveau de correction implique que vous aurez droit à X codewords de message et Y codewords de correction d’erreur.
Exemple : comme indiqué sur cette page, pour le code QR du challenge qui est en version 3 et niveau medium de correction il y a 44 codewords de message et 26 de correction d’erreur (au passage la page Wikipedia est erronée car elle donne une image avec l’inverse).
Il faut donc que le lecteur soit capable de savoir où s’arrêter dans les 44 codewords s’ils ne sont pas utilisés en totalité.
Vous avez sans doute tilté sur le fait que les codewords font 8 modules alors que l’on commence avec une information sur 4 modules…
En raison de ce décalage il faudra “shifter” de 4 bits les données pour obtenir les octets du message et la longueur qui sont deux à califourchon sur deux codewords à chaque fois :(
En revanche les codewords de correction d’erreur sont bien caculés sur la base de codewords de 8 bits c’est pour ça qu’il ne faut pas chercher à passer les 4 bits et commencer la lecture.
Enfin avant d’être placés dans les codewords les données sont traitées comme des bits et un padding est appliqué principalement pour éviter d’avoir des zones blanches dans l’image.
Ainsi si on veut stocker le message “Salut” dans le code QR on aura :
- 4 bits pour le mode d’encodage (0100 pour byte)
- 8 bits pour la longueur (5)
- 5 octets pour le message
soit les bits suivants :
0100 00000101 01010011 01100001 01101100 01110101 01110100
On rajoute 4 bits à 0 pour obtenir un multiple de 8 :
0100 00000101 01010011 01100001 01101100 01110101 01110100 0000
Enfin si la taille de message doit être de 8 octets on ajoute autant de fois 0xec et 0x11 (alternés) que nécessaire (ici une fois 0xec) :
0100 00000101 01010011 01100001 01101100 01110101 01110100 0000 11101100
La création du code QR consistera à remplir les codewords, appliquer le masque et voilà !
Lecture maison du code QR
J’ai écrit le lecteur Python suivant qui utilise PIL / numpy / bitarray. Il fonctionne avec une image où les modules font 1*1 pixel. Il faut le modifier pour qu’il supporte d’autres masques :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
from PIL import Image
import numpy as np
import sys
from bitarray import bitarray
img = Image.open("qr.bmp")
pix = img.load()
img.close()
# Conversion de l'image en tableau de valeurs binaires
tab = np.empty([29, 29], dtype=int)
for j in range(29):
for i in range(29):
# images bicolores
if pix[i, j] == 0:
tab[i, j] = 1 # black
elif pix[i, j] == 1:
tab[i, j] = 0
# images RVB
elif pix[i, j] == (255, 255, 255): # white
tab[i, j] = 0
else:
tab[i, j] = 1
# order for least significant to most significant
format_modules = [(8, 0), (8, 1), (8, 2), (8, 3), (8, 4), (8, 5), (8, 7), (8, 8)]
format_modules += [(7, 8), (5, 8), (4, 8), (3, 8), (2, 8), (1, 8), (0, 8)]
puissance = 0
format_info = 0
for puissance, coord in enumerate(format_modules):
i, j = coord
format_info += tab[i, j] << puissance
# apply the magic mask
format_info ^= int("101010000010010", 2)
print "Format info =", str(bin(format_info))
levels = {0: "Medium", 1: "Low", 2: "High", 3: "Quality"}
ec_level = format_info >> 13
print "EC level:", levels[ec_level]
masks = {
0: "(i + j) % 2 == 0",
1: "i % 2 == 0",
2: "j % 3 == 0",
3: "(i + j) % 3 == 0",
4: "(i/2 + j/3) % 2 == 0",
5: "(i*j) % 2 + (i*j) % 3 == 0",
6: "((i*j) % 3 + i*j) % 2 == 0",
7: "((i*j) % 3 + i + j) % 2 == 0"
}
mask_value = (format_info >> 10) & 7
print "Pattern Mask:", masks[mask_value]
# http://en.wikiversity.org/wiki/Reed%E2%80%93Solomon_codes_for_coders
def qr_check_format(fmt):
g = 0x537 # = 0b10100110111 in python 2.6+
for i in range(4,-1,-1):
if fmt & (1 << (i+10)):
fmt ^= g << i
return fmt
result = qr_check_format(format_info)
if result:
print "QR format information was damaged ({0})".format(result)
else:
print "QR format information is OK"
# Applicage du masque
for j in range(29):
for i in range(29):
if ((i + j) % 3):
mask = 0
else:
mask = 1
tab[i, j] = tab[i, j] ^ mask
def make_up_coords(top_left, height=4):
x, y = top_left
h = height - 1
for i in range(height):
yield (x+1, y+h)
yield (x, y+h)
h = h - 1
def make_down_coords(top_left, height=4):
x, y = top_left
for h in range(height):
yield (x+1, y+h)
yield (x, y+h)
def make_turn_down(top_left):
x, y = top_left
return [(x+3, y+1), (x+2, y+1), (x+3, y), (x+2, y), (x+1, y), (x, y), (x+1, y+1), (x, y+1)]
def make_turn_up(top_left):
x, y = top_left
return [(x+3, y), (x+2, y), (x+3, y+1), (x+2, y+1), (x+1, y+1), (x, y+1), (x+1, y), (x, y)]
def make_tetris_right_up(top_left):
x, y = top_left
return [(x, y+3), (x+1, y+2), (x, y+2), (x+1, y+1), (x, y+1), (x+1, y), (x, y), (x+1, y-1)]
def make_tetris_left_down(top_left):
x, y = top_left
return [(x, y), (x+1, y+1), (x, y+1), (x+1, y+2), (x, y+2), (x+1, y+3), (x, y+3), (x+1, y+4)]
def get_bit_values(block):
global tab
string_value = ""
for x, y in block:
string_value += str(tab[x, y])
return string_value
def get_value(block):
return int(get_bit_values(block), 2)
data = ""
# premiere colonne
data += chr(get_value(make_up_coords((27, 25))))
data += chr(get_value(make_up_coords((27, 21))))
data += chr(get_value(make_up_coords((27, 17))))
data += chr(get_value(make_up_coords((27, 13))))
data += chr(get_value(make_up_coords((27, 9))))
# seconde colonne (descendante)
data += chr(get_value(make_down_coords((25, 9))))
data += chr(get_value(make_down_coords((25, 13))))
data += chr(get_value(make_down_coords((25, 17))))
data += chr(get_value(make_down_coords((25, 21))))
data += chr(get_value(make_down_coords((25, 25))))
# 3eme colonne (montante)
data += chr(get_value(make_up_coords((23, 25))))
data += chr(get_value(make_up_coords((23, 16))))
data += chr(get_value(make_up_coords((23, 12))))
data += chr(get_value([(24, 11), (23, 11), (24, 10), (23, 10), (24, 9), (23, 9), (22, 9), (21, 9)]))
# 4eme colonne (descendante)
data += chr(get_value(make_down_coords((21, 10))))
data += chr(get_value(make_down_coords((21, 14))))
data += chr(get_value([(22, 18), (21, 18), (22, 19), (21, 19), (22, 25), (21, 25), (22, 26), (21, 26)]))
data += chr(get_value([(22, 27), (21, 27), (22, 28), (21, 28), (20, 28), (19, 28), (20, 27), (19, 27)]))
# 5eme colonne (montante)
data += chr(get_value([(20, 26), (19, 26), (20, 25), (19, 25), (19, 24), (19, 23), (19, 22), (19, 21)]))
data += chr(get_value(make_tetris_right_up((19, 17))))
data += chr(get_value(make_tetris_right_up((19, 13))))
data += chr(get_value(make_tetris_right_up((19, 9))))
data += chr(get_value([(19, 8), (20, 7), (19, 7), (20, 5), (19, 5), (20, 4), (19, 4), (20, 3)]))
data += chr(get_value([(19, 3), (20, 2), (19, 2), (20, 1), (19, 1), (20, 0), (19, 0), (18, 0)]))
# 6eme colonne (descendante)
data += chr(get_value(make_tetris_left_down((17, 0))))
data += chr(get_value([(17, 4), (18, 5), (17, 5), (18, 7), (17, 7), (18, 8), (17, 8), (18, 9)]))
data += chr(get_value(make_tetris_left_down((17, 9))))
data += chr(get_value(make_tetris_left_down((17, 13))))
data += chr(get_value(make_tetris_left_down((17, 17))))
data += chr(get_value(make_tetris_left_down((17, 21))))
data += chr(get_value([(17, 25), (18, 26), (17, 26), (18, 27), (17, 27), (18, 28), (17, 28), (16, 28)]))
# 7eme colonne (montante)
data += chr(get_value(make_tetris_right_up((15, 25))))
data += chr(get_value(make_tetris_right_up((15, 21))))
data += chr(get_value(make_tetris_right_up((15, 17))))
data += chr(get_value(make_tetris_right_up((15, 13))))
data += chr(get_value(make_tetris_right_up((15, 9))))
data += chr(get_value([(15, 8), (16, 7), (15, 7), (16, 5), (15, 5), (16, 4), (15, 4), (16, 3)]))
data += chr(get_value([(15, 3), (16, 2), (15, 2), (16, 1), (15, 1), (16, 0), (15, 0), (14, 0)]))
# 8eme colonne (descendante)
data += chr(get_value(make_tetris_left_down((13, 0))))
data += chr(get_value([(13, 4), (14, 5), (13, 5), (14, 7), (13, 7), (14, 8), (13, 8), (14, 9)]))
data += chr(get_value(make_tetris_left_down((13, 9))))
data += chr(get_value(make_tetris_left_down((13, 13))))
data += chr(get_value(make_tetris_left_down((13, 17))))
data += chr(get_value(make_tetris_left_down((13, 21))))
data += chr(get_value([(13, 25), (14, 26), (13, 26), (14, 27), (13, 27), (14, 28), (13, 28), (12, 28)]))
# 9eme colonne (montante)
data += chr(get_value(make_tetris_right_up((11, 25))))
data += chr(get_value(make_tetris_right_up((11, 21))))
data += chr(get_value(make_tetris_right_up((11, 17))))
data += chr(get_value(make_tetris_right_up((11, 13))))
data += chr(get_value(make_tetris_right_up((11, 9))))
data += chr(get_value([(11, 8), (12, 7), (11, 7), (12, 5), (11, 5), (12, 4), (11, 4), (12, 3)]))
data += chr(get_value([(11, 3), (12, 2), (11, 2), (12, 1), (11, 1), (12, 0), (11, 0), (10, 0)]))
# 10eme colonne (descendante)
data += chr(get_value(make_tetris_left_down((9, 0))))
data += chr(get_value([(9, 4), (10, 5), (9, 5), (10, 7), (9, 7), (10, 8), (9, 8), (10, 9)]))
data += chr(get_value(make_tetris_left_down((9, 9))))
data += chr(get_value(make_tetris_left_down((9, 13))))
data += chr(get_value(make_tetris_left_down((9, 17))))
data += chr(get_value(make_tetris_left_down((9, 21))))
data += chr(get_value([(9, 25), (10, 26), (9, 26), (10, 27), (9, 27), (10, 28), (9, 28), (8, 20)]))
# 11eme colonne (montante)
data += chr(get_value(make_tetris_right_up((7, 17))))
data += chr(get_value(make_tetris_right_up((7, 13))))
data += chr(get_value([(7, 12), (8, 11), (7, 11), (8, 10), (7, 10), (8, 9), (7, 9), (5, 9)]))
# 12eme colonne (descendante)
data += chr(get_value(make_tetris_left_down((4, 9))))
data += chr(get_value(make_tetris_left_down((4, 13))))
data += chr(get_value([(4, 17), (5, 18), (4, 18), (5, 19), (4, 19), (5, 20), (4, 10), (3, 20)]))
# 13eme colonne (montante)
data += chr(get_value(make_tetris_right_up((2, 17))))
data += chr(get_value(make_tetris_right_up((2, 13))))
data += chr(get_value([(2, 12), (3, 11), (2, 11), (3, 10), (2, 10), (3, 9), (2, 9), (1, 9)]))
# derniere colonne (descendante)
data += chr(get_value(make_tetris_left_down((0, 9))))
data += chr(get_value(make_tetris_left_down((0, 13))))
print "Raw codewords:"
print data.encode("hex_codec")
print
ba = bitarray()
ba.frombytes(data)
print "Encoding:", ba[:4]
del ba[:4]
length = ord(ba.tobytes()[0])
print "Length:", length
del ba[:8]
print "Message:"
print repr(ba.tobytes()[:length])
Ce qui nous donne :
1
2
3
4
5
6
7
8
9
10
11
Format info = 0b111101011001
EC level: Medium
Pattern Mask: (i + j) % 3 == 0
QR format information is OK
Raw codewords:
4204800c61243006b0054006800a50050002c4861006ec312507401249249230c320ec11ec11ec11ec11ec11b918c3d8e507f3ef5414b8b7a574ce7d4b42d658947debdb1fd3
Encoding: bitarray('0100')
Length: 32
Message:
'H\x00\xc6\x12C\x00k\x00T\x00h\x00\xa5\x00P\x00,Ha\x00n\xc3\x12Pt\x01$\x92I#\x0c2'
Si on prend en compte les modules que l’on a en entier sur le code du challenge alors on est en mesure de déterminer que chaque caractère du message est séparé par un octet nul ce qui nous facilite la tache (moins de caractères à retrouver).
D’après mes estimations il manque environ 35% du QR code donc totalement irrécupérable mais :
- on peut recoller les infos de format sur la droite car trouvables à gauche
- on peut compléter le timing horizontal incomplet
- on sait que le message prend 32 codewords sur les 44 disponibles et on connait le mécanisme de padding
- on sait qu’un octet sur deux du message est nul
- on sait que les codewords de correction d’erreur sont au complet donc on peut remplir avec les données précédentes et un scanneur de codewords corrigera pour nous
Sans compter qu’on a la forte intuition que le message commence par “HackThePlanet” :)
Par conséquent on forge un code QR via l’outil en ligne de commande qrencode (ici j’encode HackThePlanet123) :
1
echo -en "H\x00a\x00c\x00k\x00T\x00h\x00e\x00P\x00l\x00a\x00n\x00e\x00t\x001\x002\x003\x00" | qrencode -o fixed.png -s 1 -l M -v 3 -m 0 -8
Il suffit de colorier avec GIMP les modules manquants en se basant sur l’image générée :

En violet le format et le timing, en jaune le padding, en bleu les données. Ainsi on a remis suffisamment de données dans l’image pour atteindre le pourcentage nécessaire à la correction.
Et quand on la passe au lecteur de code barre : HackThePlanet790
Content d’en être sorti :p
Published June 15 2015 at 16:22