
And now for something completely different
Dear readers, this time no box pwnage, no HackTheBox or VulnHub writeup. I’ll talk about another subject I like : breaking captchas <3 and this time I will use (my somewhat broken) english language.
For those who don’t know HackThis.co.uk, it’s a website with some jeopardy challenges. Most are related to web-exploitation but the 5 captcha challenges are something you won’t probably see on lots on websites of that kind.
In this article I share how I solved the 5 captcha challenges from the easiest one to the hardest, using differents techniques.
Before I give solutions I will first give some tips (in the next section) for those of you that just want a nudge and solve the challenges by themselves.
So here we go :) HackThis Captcha challenges: Tips without solutions —————————————————
For every challenge you only have a limited time to submit a response for the captcha (10 seconds) so you will have to automate your login on the website, getting the challenge webpage, downloading the captcha and submitting the solution.
Here is a Python script you can use for this. Obviously you must change the credentials here, adapt the URLs to the given challenge and add your own code to break the captcha.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import requests
sess = requests.session()
response = sess.post(
"https://www.hackthis.co.uk/?login",
data={"username": "your_name_here", "password": "your_shitty_password_lol"}
)
sess.get("https://www.hackthis.co.uk/levels/captcha/1")
response = sess.get("https://www.hackthis.co.uk/levels/extras/captcha1.php")
with open("captcha.png", "wb") as fd:
fd.write(response.content)
try:
result = do_the_magic("captcha.png")
except ShitHappens:
print("Ohno!")
exit()
sess.post("https://www.hackthis.co.uk/levels/captcha/1", data={"answer": result})
Level 1
The simplest one. It’s just a suite of letters and symbols in green on a black background. There is a lot of possible ways to solve a captcha and you will only be limited by your own imagination.
You should try several Optical Character Recognition softwares like those mentionned here. You can expect some errors of course but if errors are always the same you can just fix them at the end by replacing bad characters.
You may also want to clean up the image (converting to black and white for example) before feeding the OCR to try to get the best results. Even if you have 0 programming experience, you can use tools from the fabulous ImageMagick suite.
Finally if you plan to train Tesseract to regnonize characters, you need the font and unfortunately its name is not mentionned on the challenge page… But maybe… you will find it in another captcha challenge ;-)
trainyourtesseract.com offer to create a .traineddata file from a font you give.
You may also prefer to work on the captcha character after character, first splitting the captcha in several smaller images. This way you are reducing the problem and can focus on a way to guess what character is printed.
Have you tried image comparison algorithms ?
Does the character in front of you have some features that can help to find its value ? Machine-learning can do almost all the stuff for you.
Level 2
Well it isn’t characters any more but smileys… Or is it ? Take a look at the source code ;-) But they may not use very common codepoints so training Tesseract will be harder.
I haven’t tried OCR on it but you never know…
Just like every captcha challenge, maching-learning can help. In fact some of the tools you will be using probably use maching-learning algorithm.
There is only 12 characters than can be used here, and one is very different from the others. Come on, it’s not that difficult :)
Level 3
Well smileys aren’t on a single line anymore and spaces between them is not regular. Basically all you have to do is find contours to extract smileys then use your previous code.
If you can’t use a library to do stuff for you, come on, it’s super easy. First split the images on whitespaces then remove empty space at the top and bottom. That’s it !
Level 4
Colors… so what ? Didn’t you wrote a script previously to clean the image and convert to black and white ? Be sure you don’t reduce image quality in such transformations.
Rotations ? Sure ! Just rotate each smiley on the 360 degrees and do the comparisons to find the best match. That’s it !
Level 5
Blurred… So what ? … I’m joking here :)
That’s where all the fun begins :) You have a clear version of a generated captcha, the blurred version and the font.
You should try to reproduce the clear captcha image first. You know HackThis is using PHP and GD is a very common library. It will be easy to find examples on the Internet ;-)
Then find the good parameters : the font size, colors and the position of the first character.
Once done, try to repeat the blur transformation. Here also, finding the same code as HackThis should be easy. You only have to find how much blur is required. Image comparison algorithms can be usefull here !
Great ! You can now produce blurred captchas just like those from the challenge page, while knowing the cleartext.
You may be thinking about generating every possible images to have some kind of rainbow database. Did you calculated how many images it represents ? And the corresponding size of your disk ? I guess no.
Comparing MD5 hashes ? Well, does your generated image perfectly match the one given by the challenge ? You may have some EXIF tags that aren’t the same. Maybe you can find a way to just compare the pixels ? Hashing them ?
That’s almost image comparison here, but should should be 100% sure of the algorithms you are using before going to far.
Cutting the image may give best results and requiring far less images to produce. Then again maching-learning is certainly the most efficient solution.
Spoiler alert
Ok I’m done with the tips. If you wan’t to solve the challenges by yourself, stop here. You may find your own methods and it will be a lot more fun. Come back when you have solved them.
Solutions
Still here ? Ok here are the solutions :)
Level 1
First step I did was cleaning the image by converting it to black and white. Basically all you have to do is convert green color to black and grey to white. But the image given by HackThis is compressed so you will have to set a threshold to determine if a color is green or not.

The following script does that stuff : creating a black and white version of a captcha image from the challenge. It uses the Pillow library but other libraries likes OpenCV can do all the stuff in less lines of codes :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#!/usr/bin/python3
from PIL import ImageFile
import sys
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
BACKG = (30, 30, 30)
GREEN = (0, 128, 0)
THRESHOLD = 150
def distance(pixel, color):
distance = 0
for i in range(3):
distance += pow(color[i] - pixel[i], 2)
return distance
def is_green(pixel):
distance_to_green = distance(pixel, GREEN)
if distance_to_green < THRESHOLD:
return True
return False
with open(sys.argv[1], "rb") as fd:
p = ImageFile.Parser()
p.feed(fd.read())
image = p.close()
img2 = image.copy()
w, h = image.size
y_start = 0xFFFF
y_end = 0
x_start = 0xFFFF
x_end = 0
for x in range(0, w):
for y in range(0, h):
if is_green(image.getpixel((x, y))):
img2.putpixel((x, y), BLACK)
x_start = min(x, x_start)
y_start = min(y, y_start)
x_end = max(x, x_end)
y_end = max(y, y_end)
else:
img2.putpixel((x, y), WHITE)
print("Box is {}/{} to {}/{}".format(x_start, y_start, x_end, y_end))
img2 = img2.crop(box=(x_start, y_start, x_end+1, y_end))
img2.save(sys.argv[1].replace(".png", "_clean.png"))
The script is also calculating the contours for the whole text, thus resulting in a smaller picture.

Now we need a script to split the cleanned image, extracting each character in a new image file.
How it works is simple : scan the picture from left to right. If you can find a black pixel then you are in a character area, continue until a column without black pixels, store the picture in another file and repeat.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
#!/usr/bin/python3
from PIL import ImageFile
import sys
import logging
import os
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
if len(sys.argv) < 1:
print("Usage: {} <captcha_file> [<solution>]".format(sys.argv[0]))
exit()
if len(sys.argv) == 3:
solution = sys.argv[2]
else:
solution = ""
with open(sys.argv[1], "rb") as fd:
p = ImageFile.Parser()
p.feed(fd.read())
image = p.close()
img2 = image.copy()
w, h = image.size
y_start = 0xFFFF
y_end = 0
x_start = 0xFFFF
x_end = 0
ranges = []
start = 0
for x in range(0, w):
is_empty = True
for y in range(0, h):
if image.getpixel((x, y)) == BLACK:
is_empty = False
break
if is_empty:
if start < x-1:
ranges.append((start, x-1))
start = x+1
ranges.append((start, w-1))
logging.debug(ranges)
if solution and len(ranges) != len(solution):
logging.error("Number of found boxes doesn't match solution length!")
exit()
for i, (x_start, x_end) in enumerate(ranges):
img2 = image.crop(box=(x_start, 0, x_end+1, h))
j = 0
while True:
if solution:
filename = "traindata/{}{}.png".format(solution[i], j)
else:
filename = "guessdata/{}.png".format(i)
if os.path.exists(filename):
j += 1
else:
img2.save(filename)
break
That script accepts an optional argument : the characters displayed in the images. If that argument is given, every new character image is named after its corresponding character.
It make it easy to use that data later, for exemple for training a machine-learning algorithm or even for just checking typing mistakes !
Pro-tip :
Keeping the original captcha images along with the corresponding text would be more clever because at some point you may not be satisfied with some previous steps (for example the color threshold was not that good or you forgot to include the last row when cutting).
By keeping the raw data you can easily modify your scripts without having to resolve captchas again. That tip can apply to every kind of data, not just captchas :)
If the optional argument (captcha solution) is not given then generated images just have their position as the name and are stored in a separate folder (guessdata against traindata).
This way I can produce a lot of images that will be used to train my tools into learning characters and I also can get a few unknown characters just to see how effective my tool can guess a character from an unlabelled image.
So now it’s time to move to the real stuff : being able to guess the good character from an image.
For this one I choosed not to use Scikit-Learn but instead a perceptual hashing algorithm called pHash. How pHash works is very well explained on The Hacker Factor Blog.
Also there is a very cool Python module called ImageHash offering several image hashing algorithms of that kind. A great advantage is that it use SciPy to calculate pHash so you won’t have to go through the difficult steps of compiling C code from phash.org :)
What does a hash from pHash looks like ?
1
2
3
4
5
6
7
8
9
10
11
12
>>> import imagehash
>>> from PIL import Image
>>> digest = imagehash.phash(Image.open("guessdata/0.png"))
>>> digest
array([[ True, True, True, True, False, False, True, False],
[False, True, False, True, True, False, False, False],
[ True, False, False, True, True, True, True, False],
[False, False, True, False, False, True, True, True],
[ True, False, True, False, False, True, False, True],
[ True, False, True, False, True, False, False, True],
[ True, False, True, False, True, False, False, False],
[ True, False, True, False, True, False, True, False]])
Exactly ! Not much, even on bigger pictures ! But it illustrates how pHashing works :)
You can also get an hex version of that matrix from imagehash (the booleans values are just converted to bits then bits to hexa).
So now it’s time to compute pHashes from an unlabelled captcha and compare thoses hashes to those of known characters :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import glob
import os
from natsort import natsorted
import imagehash
from PIL import Image
for letter_image in natsorted(glob.glob("guessdata/*.png")):
digest1 = imagehash.phash(Image.open(letter_image))
for letter_image2 in glob.glob("traindata/*.png"):
digest2 = imagehash.phash(Image.open(letter_image2))
if digest1 == digest2:
letter = os.path.basename(letter_image2)[0]
print(letter, end='')
break
else:
print('8', end='')
This script loads unknown char images from the guessdata folder and compare them using pHash to known characters from folder traindata.
If a character can’t be found, 8 is used as a substitution.
It works well :
1
2
$ python solve.py
xOUlx*&gHHNofGbfKTNnQcHcGDdmmZWi#O&MXW-W
For your information I had only 440 known character images in my traindata folder. Not that much !
You would have to glue the several scripts and install the dependancies to complete the challenge. But if you are reading those lines it means you gave up or you are just curious. Do not cheat ! Stop reading here and try solving the next one :)
Level 2

Let’s move to smileys ! If you pay attention you should see in the challenge webpage source that the caption is not made of pictures but characters.
It’s not hard to discover that thoses smileys come from a font called icomoon.
Using a tool like gucharmap you can explore unicode characters in that font and finally finding the smileys :
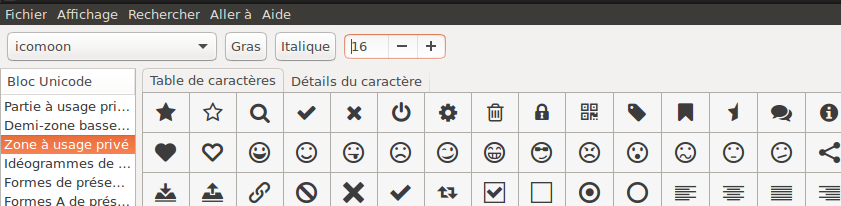
Using a tool like Pango you should even be able to generate your own captcha images :
1
2
printf "\uE025\uE02B" > blackheart_and_wink.txt
pango-view --font=icomoon,16 --margin=0 blackheart_and_wink.txt
Or using Python with Pillow :
1
2
3
4
5
6
7
8
9
10
import PIL
from PIL import ImageFont
from PIL import Image
from PIL import ImageDraw
font = ImageFont.truetype("/path/to/icomoon.ttf", 16)
img = Image.new("RGBA", (16, 16), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.text((0, 0),"\ue025", (0, 0, 0), font=font)
img.save("heart.png")
Making it super-easy to break the challenge using machine-learning (exercice is left to the reader).
Method I used personnaly is aproximately the same as the one for level 1 expect I used dHash (difference hashing) as a reinforcement algorithm.
Also here I’m not just checking if two hashes are identical but I’m calculating the distance between those two to see how much they are similar. That’s a great feature of thoses hashes so let’s use it !
Cleaning and cutting the picture is almost the same process. You only have to name each captchas as you won’t be able to put a slash in a filename.

My solving script looks like this :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import glob
import os
from natsort import natsorted
import imagehash
from PIL import Image
WHITE = (255, 255, 255)
smileys = [
(":D", "happy"),
(":)", "smiley"),
(":p", "tongue"),
(":(", "sad"),
(";)", "wink"),
("B)", "cool"),
(":@", "angry"),
(":o", "shocked"),
(":s", "confused"),
(":|", "neutral"),
(":/", "wondering"),
("<3", "heart")
]
def filename_to_smiley(filename):
for symbol, name in smileys:
if filename.startswith(name):
return symbol
return ""
dhash_digests = {}
phash_digests = {}
for letter_image in glob.glob("traindata_fixed/*.png"):
dhash_digest = imagehash.dhash(Image.open(letter_image))
phash_digest = imagehash.phash(Image.open(letter_image))
letter = filename_to_smiley(os.path.basename(letter_image))
dhash_digests[dhash_digest] = letter
phash_digests[phash_digest] = letter
for letter_image in natsorted(glob.glob("guessdata/*.png")):
min_distance = 0xFFFF
letter = "?"
img = Image.open(letter_image)
digest = imagehash.dhash(img)
for known_digest in dhash_digests:
distance = digest - known_digest
if distance < min_distance:
min_distance = distance
letter = dhash_digests[known_digest]
digest = imagehash.phash(img)
for known_digest in phash_digests:
distance = digest - known_digest
if distance < min_distance:
min_distance = distance
letter = phash_digests[known_digest]
print(letter, end=' ')
And of course it works !
1
2
python bisolve.py
:s :p :D :p ;) :@ :p :o <3 :) <3 :o ;) <3 :/
This time I had 120 images in the traindata_fixed folder because we have less characters to recognize.
Level 3
Same player, play again !
Converting color is exactly the same process but as smileys aren’t on a single line any more we must calculate their ordinates when cutting.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
#!/usr/bin/python3
from PIL import ImageFile
import sys
import logging
import os
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
if len(sys.argv) < 1:
print("Usage: {} <captcha_file> [<solution>]".format(sys.argv[0]))
exit()
smileys = [
(":D", "happy"),
(":)", "smiley"),
(":p", "tongue"),
(":(", "sad"),
(";)", "wink"),
("B)", "cool"),
(":@", "angry"),
(":o", "shocked"),
(":s", "confused"),
(":|", "neutral"),
(":/", "wondering"),
("<3", "heart")
]
known_smiles = [smile[0] for smile in smileys]
def get_filename(smiley):
for symbol, name in smileys:
if symbol == smiley:
return name
return ""
if len(sys.argv) == 3:
solution = sys.argv[2].split()
for smile in solution:
if smile not in known_smiles:
print("Invalid smiley {} given in solution".format(smile))
exit()
else:
solution = []
with open(sys.argv[1], "rb") as fd:
p = ImageFile.Parser()
p.feed(fd.read())
image = p.close()
img2 = image.copy()
w, h = image.size
ranges = []
start = 0
for x in range(0, w):
is_empty = True
for y in range(0, h):
if image.getpixel((x, y)) == BLACK:
is_empty = False
break
if is_empty:
if start < x-1:
ranges.append((start, x-1))
start = x+1
ranges.append((start, w-1))
logging.debug(ranges)
if solution and len(ranges) != len(solution):
logging.error("Number of found boxes doesn't match solution length!")
exit()
for i, (range_start, range_end) in enumerate(ranges):
print("Processing range {}-{}".format(range_start, range_end))
y_start = 0xFFFF
y_end = 0
for y in range(h):
for x in range(range_start, range_end):
if image.getpixel((x, y)) == BLACK:
y_start = min(y, y_start)
y_end = max(y, y_end)
img2 = image.crop(box=(range_start, y_start, min(range_end+1, w), y_end))
j = 0
while True:
if solution:
filename = "traindata/{}{}.png".format(get_filename(solution[i]), j)
if os.path.exists(filename):
j += 1
continue
else:
filename = "guessdata/{}.png".format(i)
img2.save(filename)
break
That’s it ! The previous solving script will work the same way, using the exact same data we collected previously.
Level 4
Changes from the previous challenge are random colors used for smileys and rotation.
While color isn’t really a problem (background color haven’t changed), we should be careful at how we deal with rotation.

The solution I choosed is once again tied to pHash. It works but it’s not very accurate and requires lot of samples and processing. So feel free to use your own method :)
I collected about 2000 samples of smileys in the way they were displayed in the captcha (with a random rotation).
For each sample I performed a 180° rotation (from -45 to 45, skiping half the degrees, meaning I made 90 rotations) and for each transformation calculated the pHash.
So I have 2000 * 90 = 180000 hashes. Of course we have to do the calculus on the training data before fetching the captcha image (it takes a few minutes to process the hashes).
1
2
3
4
5
6
7
8
9
10
11
digests = {}
for i, letter_image in enumerate(glob.glob("traindata/*.png")):
img = Image.open(letter_image)
for degree in range(-45, 45, 2):
rotated = img.rotate(degree, expand=1, fillcolor=WHITE)
digest = imagehash.phash(rotated)
letter = filename_to_smiley(os.path.basename(letter_image))
digests[digest] = letter
if i % 100 == 0:
print("Status", i)
Then for solving I extract each smiley, rotate them from -2° to 2° and find the nearest hash in my collection of 180000 to determine the corresponding smileys.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
results = []
for letter_image in natsorted(glob.glob("guessdata/*.png")):
print("processing", letter_image)
min_distance = 0xFFFF
letter = "?"
img = Image.open(letter_image)
for degree in range(-2, 2):
rotated = img.rotate(degree, expand=1, fillcolor=WHITE)
digest = imagehash.phash(rotated)
for known_digest in digests:
distance = digest - known_digest
if distance < min_distance:
min_distance = distance
letter = digests[known_digest]
results.append(letter)
result = "".join(results)
It works but as I said it have many drawbacks :
- Requires too many samples
- Processing time is slow
- Not enough accurate
| What to learn here ? Cleaning process should be flawless ! In my samples it was sometimes hard to guess if a smiley was :/ or : |
If it’s hard to see the differences with human eyes then the computer will have some difficulties too.
I should have maybe enlarged the images first or make the conversion to black and white smoother… or both. With samples of better quality you need less samples thus processing takes less time.
Level 5
Here we have captchas made up of 5 characters (letter or digit) that have been blurred. We have the used font called unispace. We have a clear version of a captcha along with it’s blurred version.
How the f*ck do you solve this ? Well, one problem at a time !

First thing to do is try to reproduce the identical clear image. All we have to do is find the right colors, font size and (x, y) coordinates for the begining of the text.
I finally reached those parameters (let’s call this script write.php):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
<?php
// Create the image
$im = imagecreatetruecolor(90, 40);
// Create some colors
$backg = imagecolorallocate($im, 30, 30, 30);
$green = imagecolorallocate($im, 0, 128, 0);
imagefilledrectangle($im, 0, 0, 89, 39, $backg);
// The text to draw
$text = $argv[1];
// Replace path by your own font path
$font = './unispace.ttf';
// Add the text
imagettftext(
$im,
13, // font size
0, //angle
15, // x
27, // y
$green, $font, $text);
imagepng($im, "$argv[1].png");
imagedestroy($im);
?>
Can you spot the differences between those images ? One is provided by the challenge, one is my own generated image :
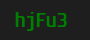
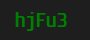
No let’s move to bluring ! Bluring images in PHP using GD is not complicated but we need to find how many times the blur filter have been applied on the text.
So let’s generate some blurred version of the provided image from a somewhat blurred version to a very blurred one :
1
2
3
4
5
6
7
8
9
10
<?php
for ($blurs = 10; $blurs < 41; $blurs++) {
$image = imagecreatefrompng('example.png');
for ($i = 0; $i < $blurs; $i++) {
imagefilter($image, IMG_FILTER_GAUSSIAN_BLUR);
}
imagepng($image, "blur$blurs.png");
imagedestroy($image);
}
?>
pHash will prove useful once again, comparing provided blurred image to the ones I generated :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from PIL import Image
import imagehash
ref_hash = imagehash.phash(Image.open("example_blur.png"))
min_distance = 0xFFFF
corresp = -1
for blur in range(10, 31):
ph = imagehash.phash(Image.open("blur{}.png".format(blur)))
distance = ref_hash - ph
if distance < min_distance:
min_distance = distance
corresp = blur
print("min distance:", min_distance)
print("match:", corresp)
We have a winner !
1
2
min distance: 0
match: 25
We can now modify our write.php script to do the 25 iterations of blur.
Using pHash to solve this challenge would be a bad idea though. Images are made of 5 characters that can be letters or digits so we have :
1
pow(len(string.ascii_letters + string.digits), 5) == 916132832
A generated blurred image size is small (approximately 1100 bytes) but to cover every combination you will have to use 938,54 GB of disk space !
Even if you delete each image once you calculated the hash you still need to store 6,83 GB of hashes.
And finally, guess what ?

That’s right ! I let a script calculates hashes just for two days and I found 224 collisions for a hash I took randomly. So abciu produce the same hash as abclu, abc1u but also abyQu, abA5o, ahElx or akLCw.
pHash is not that good on blurred images. We reached its limits.
We will use machine-learning with Scikit-Learn this time but first we must reduce the amount of samples to generate.
Obviously when blur is applied, only characters directly next to another have an effect on it. So to have blurred samples for images with a leading ‘a’ we can compute ‘ab’, ‘ac’… ‘aZ’, ‘a0’… ‘a9’ but we don’t care computing ‘abG5h’ for example.
To compute images with a ‘H’ in second position we only have to compute combinations for the 3 first characters.
Sum of those reduced combinations is :
1
pow(62, 2) + pow(62, 3) + pow(62, 3) + pow(62, 3) + pow(62, 2) == 722672
We just divided the amount of work by 1267 ! I reduced even more that number by skipping some possible adjacents characters (taking only 1 out of 3).
In my following script I’m extracting each blurred character. I’m using hardcoded box coordinates because characters position doesn’t change.
No need to write each extracted character to a new picture : I’m directly putting the pixel values in a matrix that will be used to train my model (learning).
Final note : I’m iterating through character position (1 to 5), generating a model for each position so at the end I will have 5 pickle files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
import os
import string
from itertools import product
from PIL import Image
from sklearn.externals import joblib
from sklearn import svm
import numpy as np
chars = string.ascii_letters + string.digits
# absices ranges, included
boxes = [
(14, 25),
(26, 34),
(35, 45),
(46, 56),
(57, 67)
]
y_min = 10
y_max = 35
height = 25
for i in range(5):
print("Working on position", i+1)
lists = ['a'] * 5
min_pos = max(i-1, 0)
max_pos = min(4, i+1)
x_min, x_max = boxes[i]
for j in range(min_pos, max_pos+1):
if j == i:
lists[j] = chars
elif j == i-1 or j == i+1:
lists[j] = chars[::3]
clf = svm.LinearSVC()
matrices = []
targets = []
for candidate in product(*lists):
word = "".join(candidate)
os.system("php write.php {}".format(word))
img = Image.open("blur_{}.png".format(word))
letter = img.crop(box=(x_min, y_min, x_max+1, y_max)).convert("L")
width = x_max - x_min + 1
lines = []
for y in range(height):
rows = []
for x in range(width):
rows.append(letter.getpixel((x, y)))
lines.append(rows)
os.unlink("{}.png".format(word))
os.unlink("blur_{}.png".format(word))
matrices.append(np.array(lines).ravel())
targets.append(candidate[i])
clf.fit(matrices, targets)
joblib.dump(clf, "char{}.pkl".format(i))
No let’s move to our captcha breaker. This script will extract pixels from a given captcha image, and pass each matrices to the corresponding model to predict() which character is blurred.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def break_captcha(filename: str) -> str:
chars = string.ascii_letters + string.digits
# absices ranges, included
boxes = [
(14, 25),
(26, 34),
(35, 45),
(46, 56),
(57, 67)
]
y_min = 10
y_max = 35
height = 25
result = ""
for i in range(5):
print("Working on position", i+1)
img = Image.open(filename)
min_pos = max(i-1, 0)
max_pos = min(4, i+1)
x_min, x_max = boxes[i]
letter = img.crop(box=(x_min, y_min, x_max+1, y_max)).convert("L")
width = x_max - x_min + 1
lines = []
for y in range(height):
rows = []
for x in range(width):
rows.append(letter.getpixel((x, y)))
lines.append(rows)
data = np.array(lines).ravel()
clf = joblib.load("char{}.pkl".format(i))
result += clf.predict([data])[0]
return result
How effective is it ? Well, I solved it on first attempt so I guess that’s not bad :D
Conclusion
Breaking captcha is fun and few websites offer that kind of challenge. Thank you HackThis !
Here we saw how we could leverage image hashing algorithms to solve weak captchas and also how we can break some strong captchas using maching-learning and public information (font used).
Published November 23 2018 at 18:06